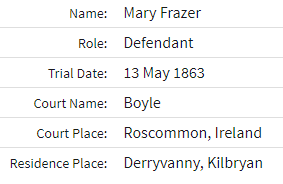
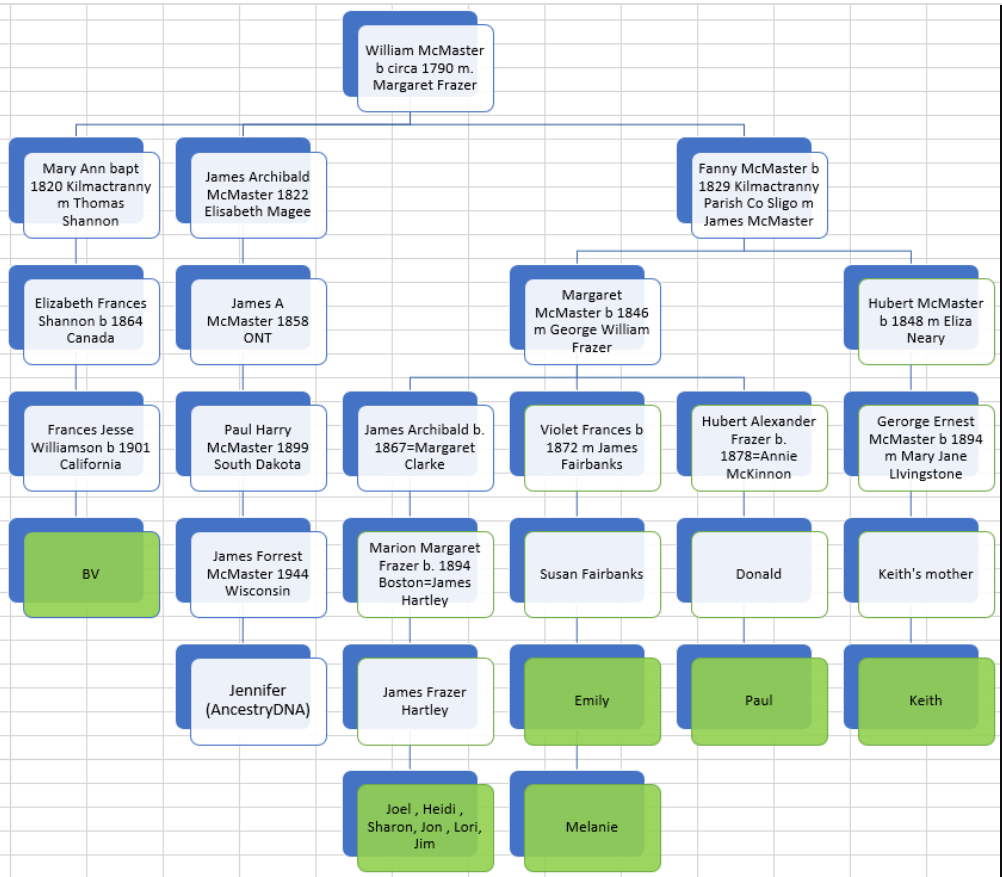
Several years ago, I worked on the visual phasing of my wife’s paternal side. I administer the DNA for my wife’s father and two aunts. That gives me enough information to do visual phasing. I downloaded the Stephen Fox spreadsheet, but this does not work well now. That means that I can just update my old excel individual Chromosome maps.
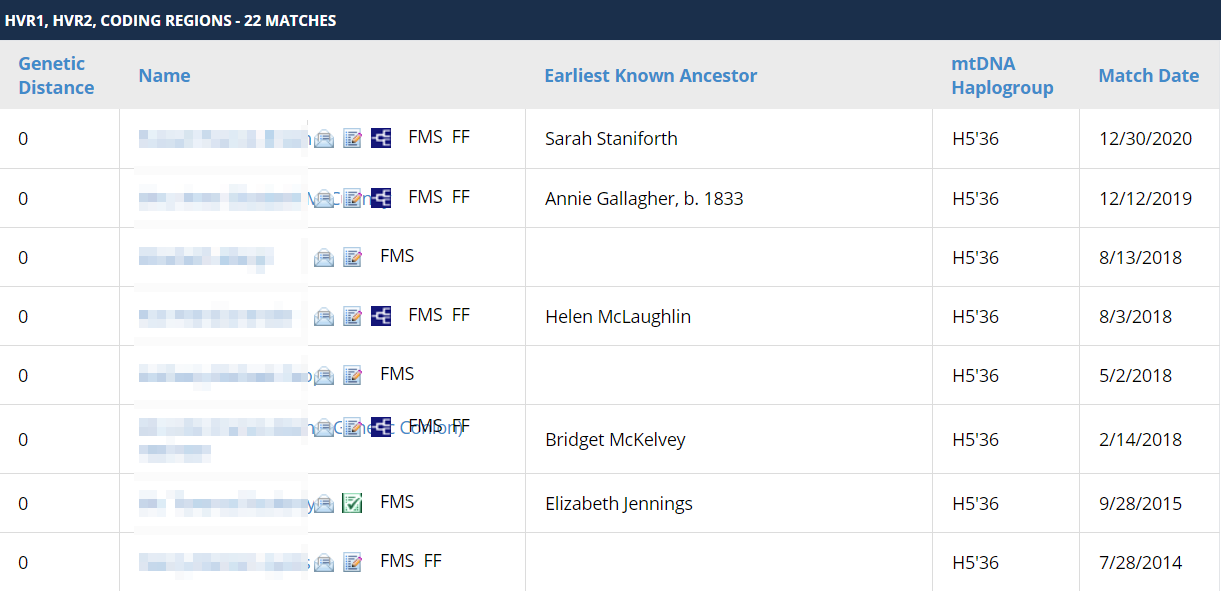
New Butler Matches
Part of the problem I had with visual phasing of the Butler family is that there were a lot of matches on their maternal French Canadian side, but not as many matches on their Irish side. In there past several years, there should be new matches that could help in identifying the paternal grandparents.
Chromosome 2
This is what I had for Chromosome 2 – last worked on in 2018:

Here Gaby is not very helpful as she is a first cousin. Here is another match on Chromosome 2:

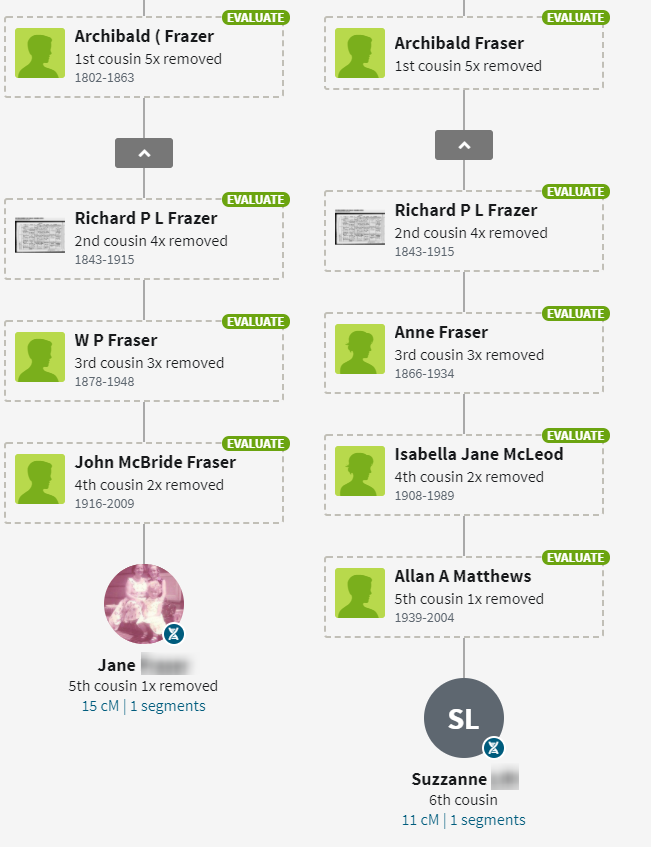
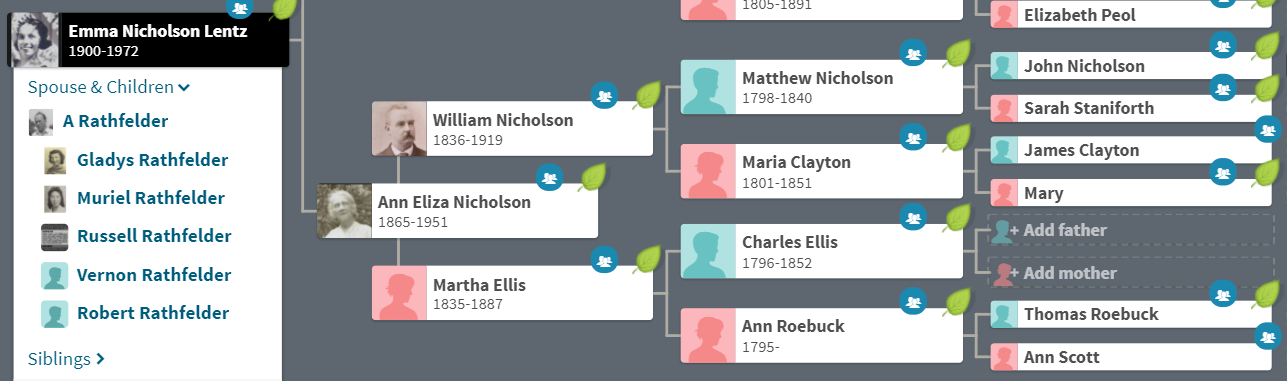
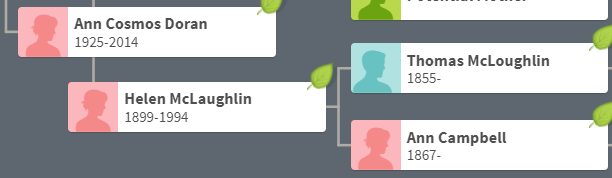
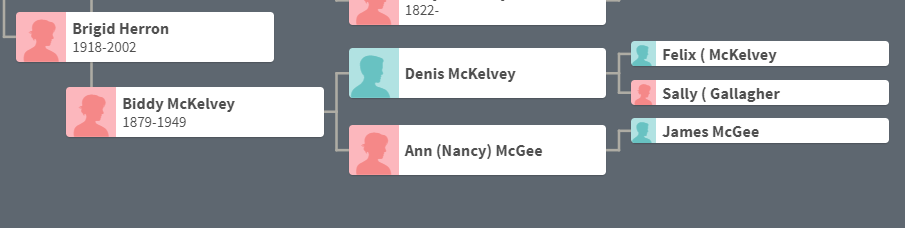
Lorraine and John are 2nd cousins, once removed on the Kerivan side. Here is how John and Lorraine match:

John will be even more helpful on Chromosomes 7, 15 and 20.
The position of 227M is significant as it occurs at a crossover. Here is John’s match with Virginia:

Here is John and Richard:

This shows that my former Chromosome 2 map was wrong on the right. All the DNA on the right should be Kerivan and not Butler. I’m a bit out of practice with these, so I’ll move on to Chromosome 7 which I hope will be easier.
Chromosome 7
Here is what I had for Chromosome 7 back in 2017:

It looks like I was having trouble with this one also as I have two different tries. I can now see by Richard’s match with John, that his crossover at 83 is on the paternal side:

Following John’s matches, it appears that this could be the answer:

This is a case where one good match can map both the paternal and maternal sides of a whole Chromosome. While that is good, you can see that there is quite a bit of Butler [green] DNA missing between these three siblings. It would be a good idea to verify the maternal side. I checked MyHeritage and Fred matches Virginia there on Chromosome 7 where I show Fred’s sister matching between about position 70 and 80. That confirms my earlier work. It is satisfying to have this Chromosome finished.
Summary of Butler Chromosomes
It would make sense to summarize the condition of the Butler 23 chromosomes in a spreadsheet.

It took a while to go through all my files. This shows that six out of 23 chromosomes are phased by grandparent. At this point, I will assume that the green highlighted chromosomes are correct. Next I can leither look at the yellow highlighted chromosomes or revisit the Butler matches with John on the Kerivan side.
Chromosome 4
This Chromosome was analyzed in PowerPoint which is not ideal:
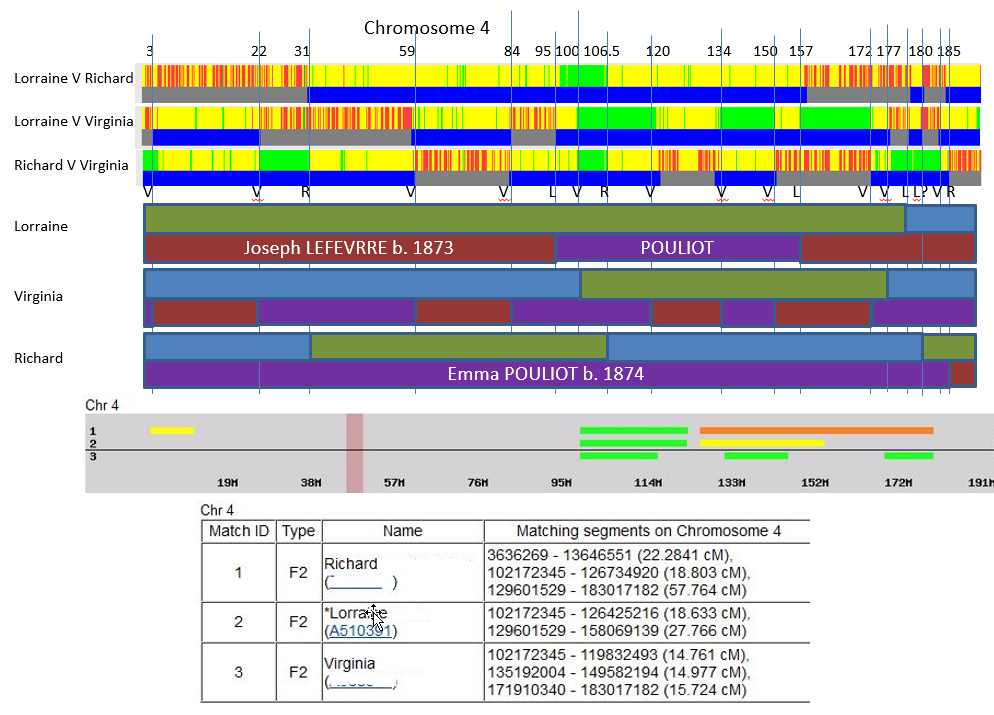
These larger chromosomes can have a lot of crossovers. Fortunately, we now have John’s DNA match at Gedmatch. From above, I see:
- John doesn’t match Lorraine
- John matches Virginia in three places
- John matches Richard in one place near the right end of Chromosome 4 (at 183 to 185)
From this it seems obvious that Butler is green and Kerivan is blue on the map above. This is how the paternal side comes out:

Richard’s match to John ends at 185, so that describes his last paternal crossover at 185. VIrginia’s match to John is from 183 to 189. The question then is why doesn’t Lorraine match John on the right side of the Chromosome if she shows blue Kerivan there? I can show more detail on the match between Lorraine and John:

I’m really showing nothing – especially on the right hand side. That means that Lorraine should be all Butler maternally and other adjustments have to be made. Here is my correction for the right side of Chromosome 4 which appears to be closer to the truth:

I moved Richard’s crossover to 185. I ignored the two crossovers for Lorraine.
Back to Chromosome 2
I will stay with the John matches and see if I am closer to tackling Chromosome 2. Here I added John’s DNA matches at the bottom:

Because Virginia matches John sooner than Richard and Lorraine do on the right, this could indicate multiple crossovers. I’ll take out the last Virginia crossover and add in two for Richard and Lorraine.

I’m not sure how I would have figured out that there was a double crossover at 227.5 were it not for the match the Bulter family has with John.
Chromosome 6
Here John matches only Virginia:
![]()
That small match identifies green as Kerivan:

However, it raises the question as to why Lorraine does not match John between positions 103 and 108. When I lower thre threshold, I see that she does:

That tells me that this was a valid match between Lorraine and John. It just got clipped on both ends. This also confirms Lorraine’s paternal crossover at about 107.5.

John’s DNA Match and Chromosome 8
John matches Virginia only on Chromosome 8:
![]()
Here is what I had done previously on Chromosome 8:

John’s match with Virginia is to the far right of Chromosome 8. That means that blue is Kerivan and Green is Butler.

John’s match with Virginia did not define any new crossovers but it did make the work that I did previously more useful. For example, if Richard comes across a paternal match on the right side of Chromosome 8 at 75 or higher, it will be on the Butler side.
Chromosome 9
John matches Virginia and Richard (but not Lorraine) on the same area:
![]()
I had already ‘solved’ Chromosome 9 previously, but let’s see if John’s two matches fit in:

I see already that I had a labeling error as I have Butler in the orange and green segments. Also I have Lorraine and Virginia as the same paternal color which is wrong. Problems. Here is the link to the Blog where I made the mistakes. This was how I had Chromosome 9 before I went wrong:

It seems like this is a better rendering of Chromosome 9:

I changed Virginia’s first crossover to her maternal side. This is because she matches John who has Kerivan ancestry at position 8-14. I notice again, if I mapped this right, that the Butler DNA is skimpy. If there is a big Butler match waiting to be found in the middle of Chromosome 9, it will not be found by these three siblings.
Chromosome 10
Virginia and John match on Chromosome 10:
![]()
Right now I have no names on Chromosome 10:

I would need more matches to figure out if that is maternal or paternal.
At MyHeritage:

Here is the DNA match:

Lorraine’s match to Philip looks the same:

Philip and Richard do not match on Chromosome 10:

Unfortunately, even that does not help. Thinking a bit more, the first match between John and Virginia does help:

That match with John representing Kerivan must be on the salmon color. That is because no one else matches Virginia’s salmon color in that area of the match. If the match was in the green, then Lorraine would also have to match John there. This appears to be the answer:

From looking at first cousin matches previously, I seem to have figured out the maternal and paternal sides of this Chromosome.
Chromosome 12
John matches Virginia and Richard here:
![]()
I had already figured out Chromosome 12:

The match with John supports the mapping on the right as Lorraine shows Butler in yellow.
Chromosome 15
Just two chromosomes to go. John matches Lorraine here:
![]()
Some of my early visual phasing was done in Word:

Virginia matches known 2nd cousin Fred at MyHeritage:

Here is the DNA match:

Here is Lorraine and Fred:

This suggests a maternal crossover for Virginia at about position 28
I’m going to try to start Chromosome 15 again. This time in Excel:

I put in who owns the crossovers and most of the positiongs. I started at the right where Lorraine and Richard have no matches, so opposite colors. I then moved Lorraine’s colors to her next crossover. Lorraine and Virginia have a Fully Identical Region (FIR) in green so I added that in. Next, I’ll do a random half identical region between Lorraine and Virginia and see where that goes.

That looks better. It is all done except for the left side. I now see that John’s match with Lorraine must be on the salmon color. That is because John matches only Lorraine and not Virginia nor Richard. That means that salmon represents the Kerivan quarter and blue the Butler quarter.

Now I just need to look at the two Pouliot matches from MyHeritage. This should be the finished Chromosome 15 for Richard, Lorraine and Virginia:

That match between Fred, Lorraine and Virginia helped define two maternal crossovers. One was at 28 and one at 33. These were a little off from where I drew the original crossover lines at 27 and 31. On this Chromosome, some Pouliot DNA was lost between the three siblings from 60 to 95. I put Richard’s crossover at35 on his paternal side as he should have had a match with Fred (Pouliot side) if his crossover was on the maternal side.
Chromosome 20

Chromosome 20 looks fairly simple. I used a first cousin match somehow to come up with the map. Lorraine and Richard have this match with John (Kerivan side):
![]()
The way I mapped it, Virginia and Richard have the same Paternal grandparent. That means that I made a mistake or that the match is wrong. The one place I can go to for matches by Chromosome is DNAPainter. I have painte some of Richard’s DNA there:

This shows no paternal matches for Richard, but matches with two people on the maternal side. Michelle is at FTDNA here grandfather was Joseph Martin LeFevre. Richard descends from a first wife and Michelle from a second wife. That means that there is only one common ancestor between Michelle and Richard. From DNAPainter, I see that the match is from 0-8. That means that LeFevre is right for the left part of Richard’s
Line is at Gedmatch and goes back to Delisle who is on the LeFevre line. This would also be correct for the right side of Richard’s Chromosome 20. Here is Line and Lorraine:

That means that the right side of Lorraine’s Chromosome 20 is right. I don’t see Line matching Virginia at Gedmatch, so that would support the right side of Virginia’s Chromosome 20 also.
At this point, I’m at an impasse. It could be that Virginia has two extra crossovers here:

I’ll just leave this Chromosome as is for now and try to solve it later.
Summary and Conclusions
Here is my spreadsheet:

- I went from 5 to 10 chromosomes completed.
- I corrected one Chromosome I thought had had completed previously (Chromosome 9).
- I improved some chromosomes without solving them, making them more useful
- The chromosomes were helped by a match to second cousin once removed John. He has his DNA at Ancestry and at Gedmatch.
- MyHeritage was also helpful as they have ‘Theories of Relativity’ which give likely common ancestors and have detailed chromosome matching information.
- Finally, DNAPainter is helpful in looking at specific chromosomes to see who the matches are there.
- I will need to follow up on ‘painting’ Virginia and Lorraine.
- I will also need to follow up on working on completing more of the visual phasing for the DNA of siblings Richard, Lorraine and Virginia.