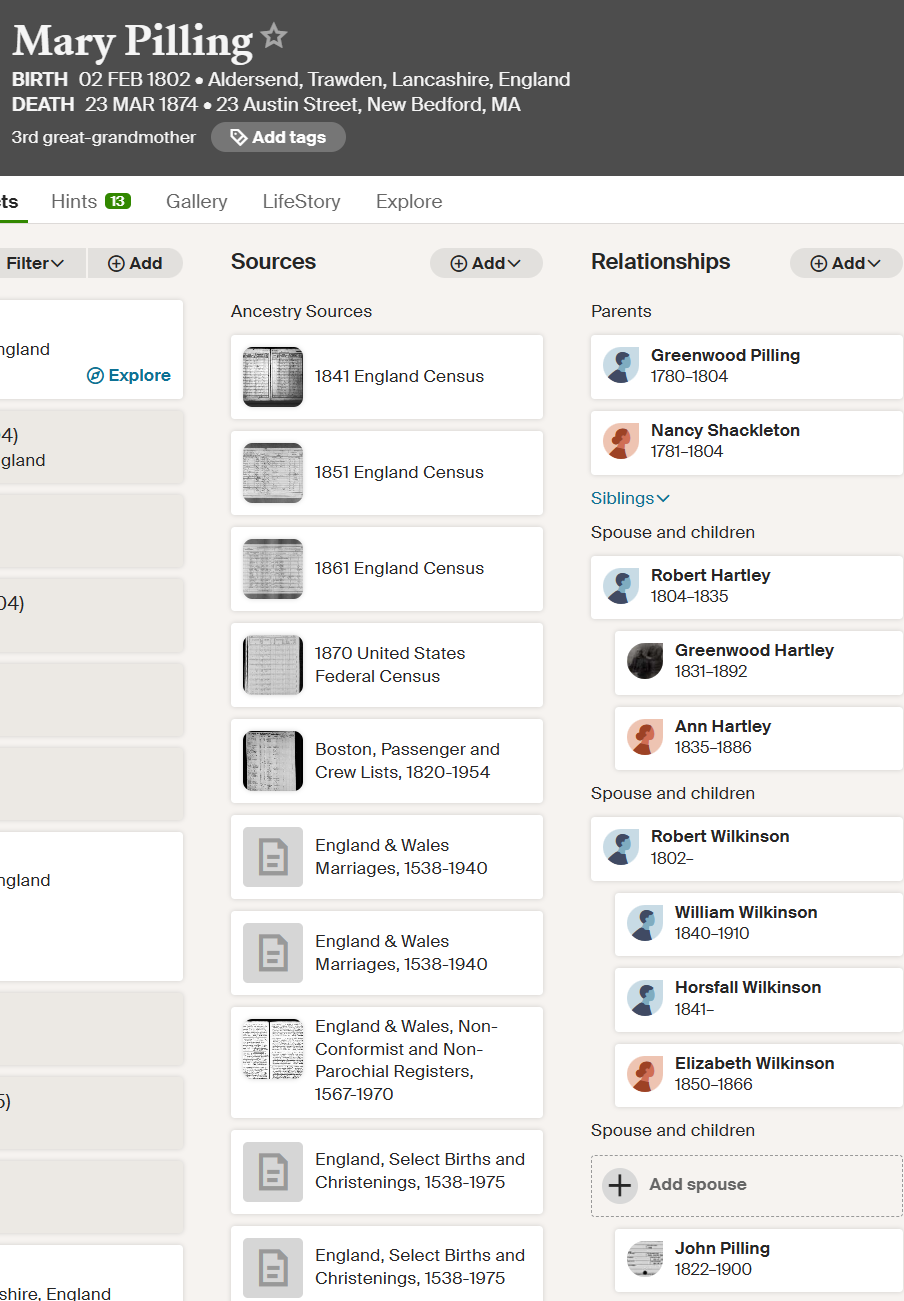
I like looking at Ancestry’s potential common ancestors at Ancestry. In this case, my brother Jon’s DNA match is with Anita. The part which is less sure is the genealogy. Even if the genealogy is right, there is a chance that the DNA/genealogy connection could be with another ancestor. However, the fact that there is a DNA connection makes it more likely that there is a discernable genealogical connection.
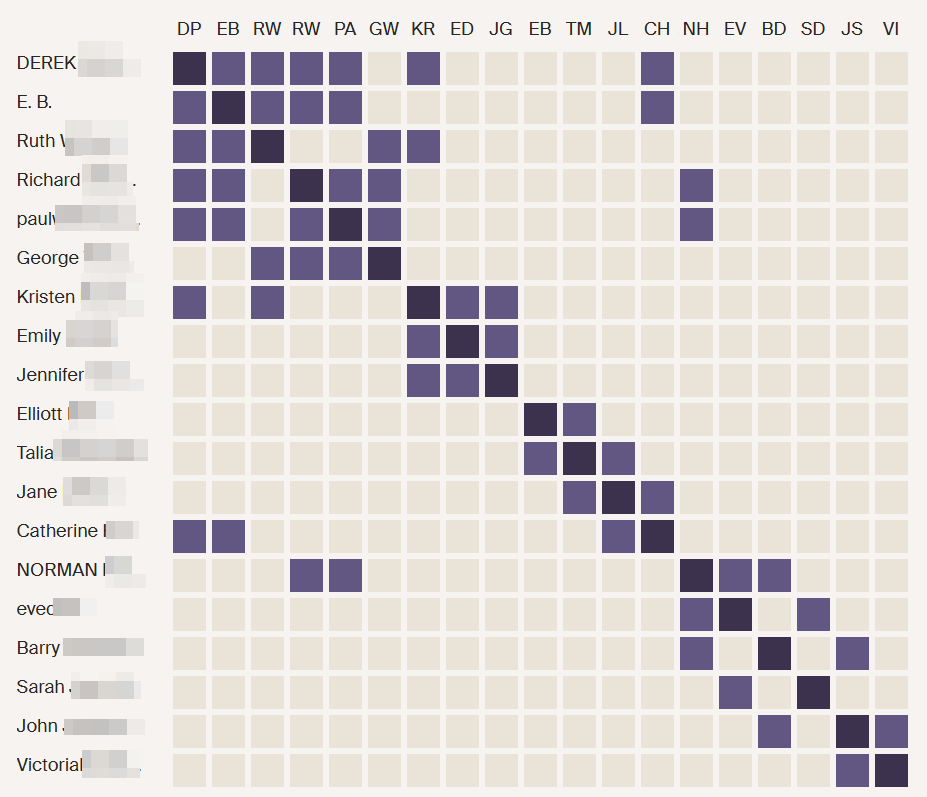
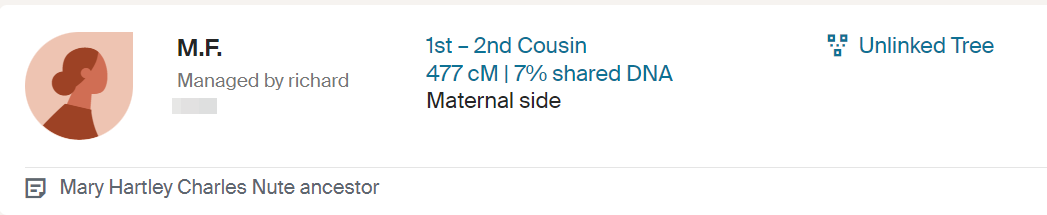
Anita and Jon
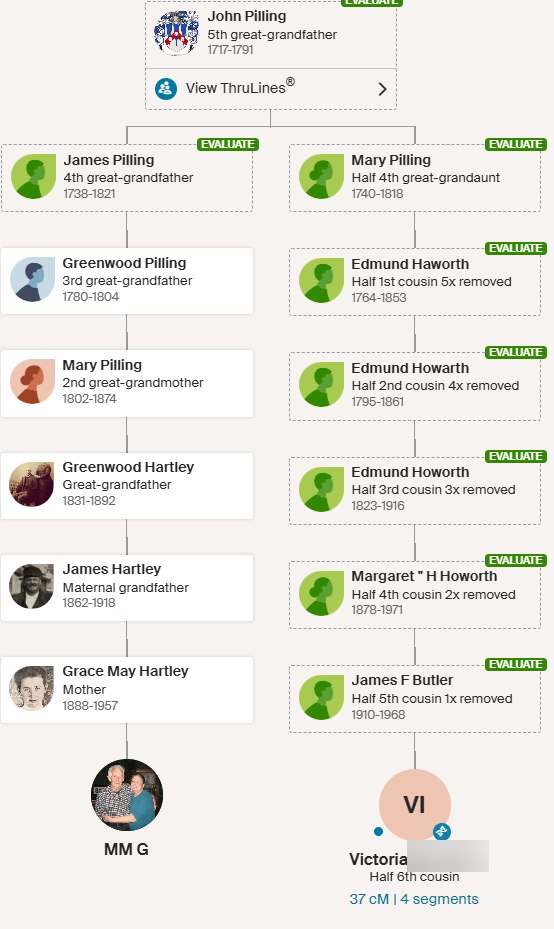
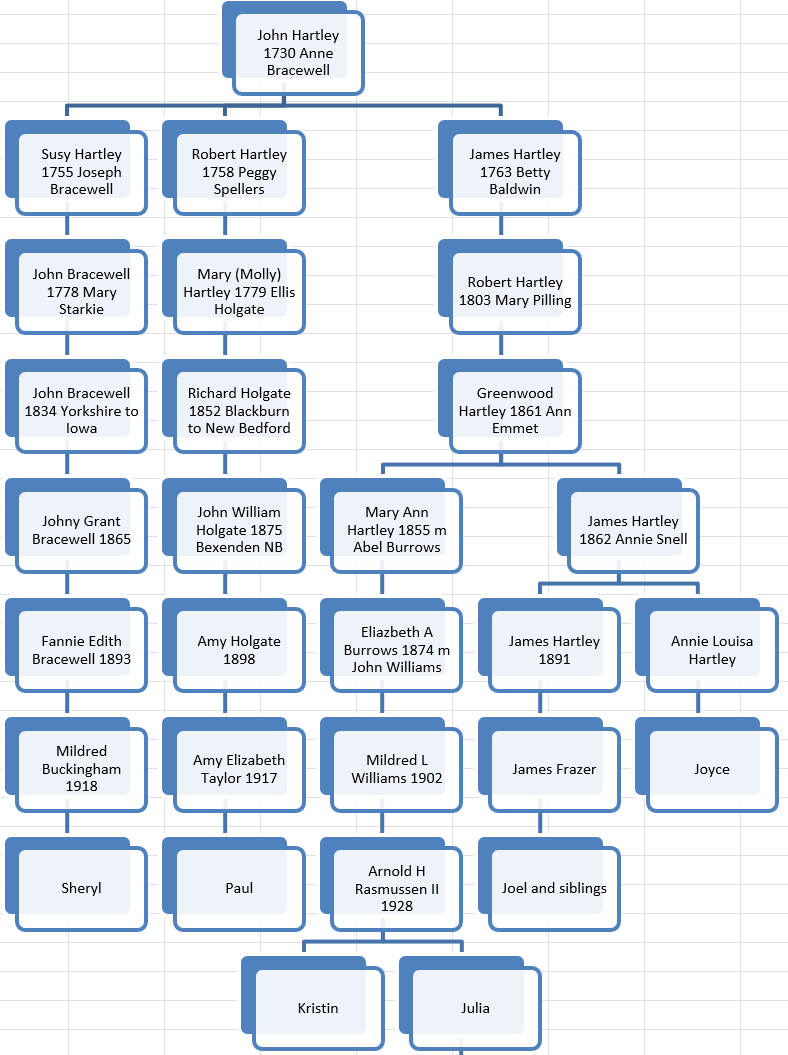
Anita and Jon are shown as 6th cousins. This is as far out as these Ancestry connections go.
Shared Matches
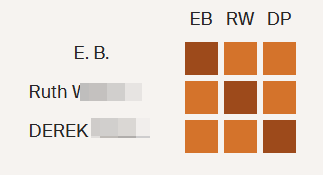
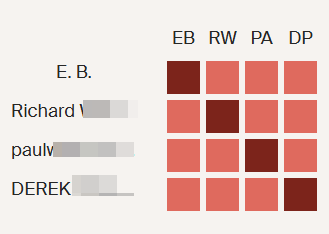
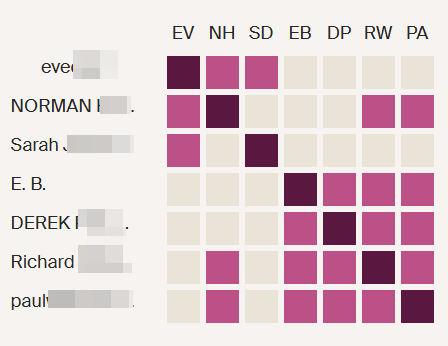
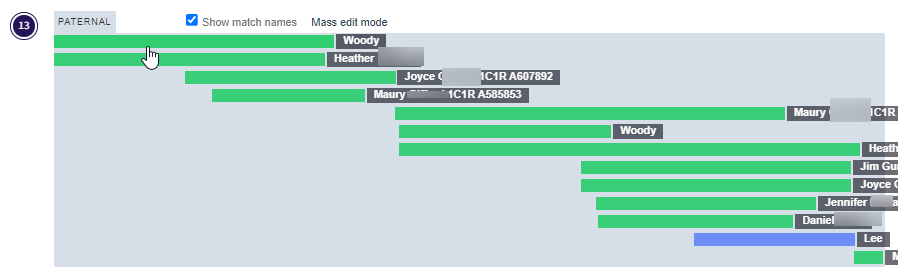
Next, I like to check shared matches:
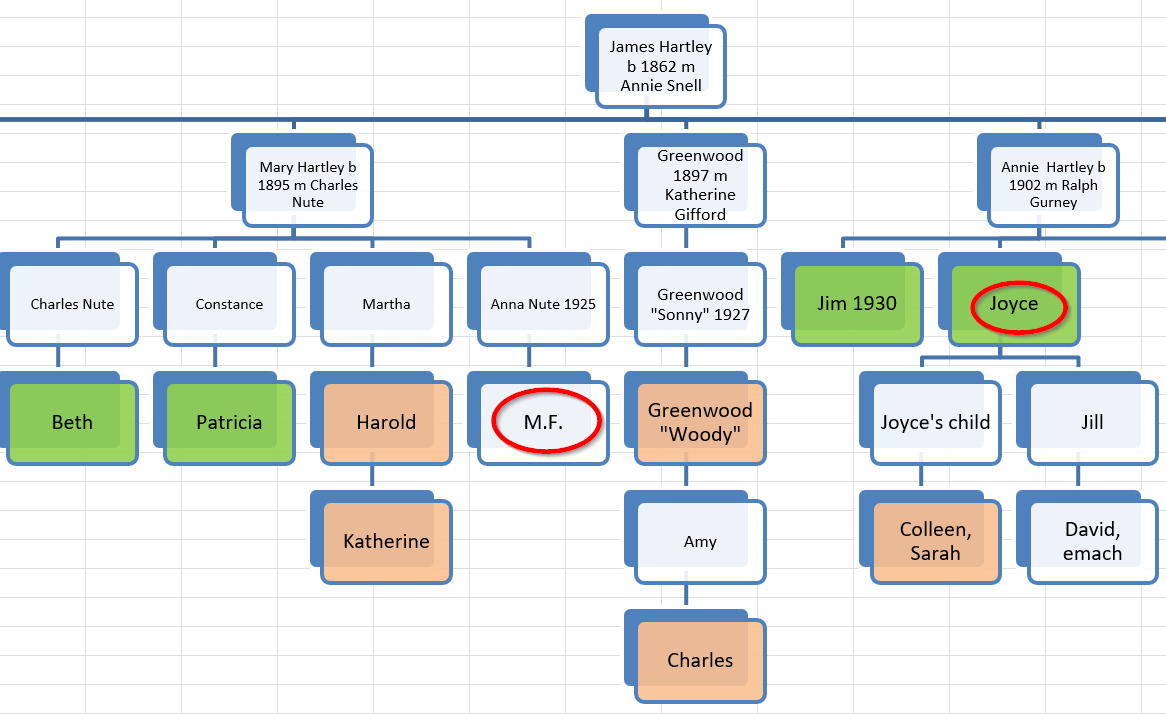
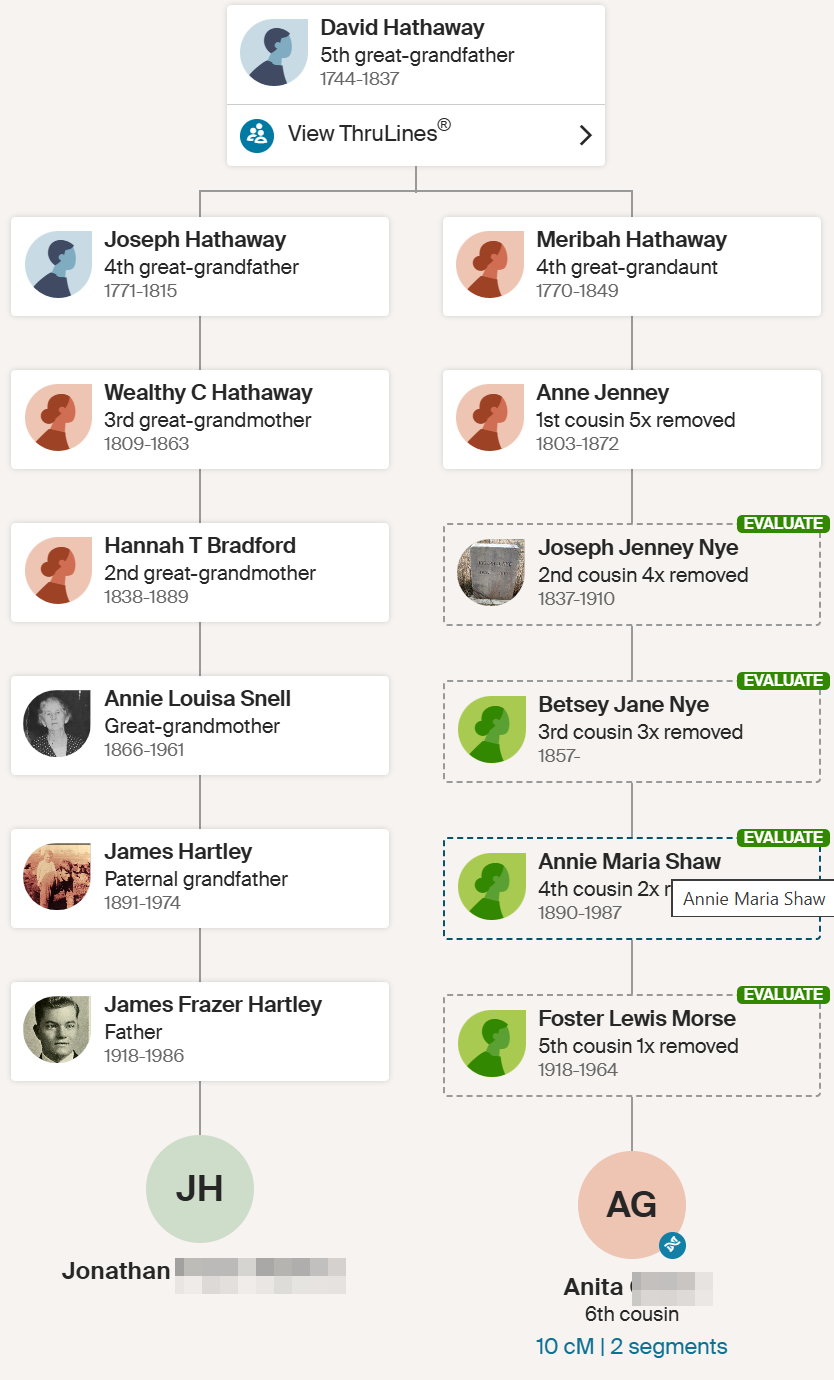
Dawn is a shared match. She also has a Hathaway common ancestor as Harvey Bradford married Wealthy Hathaway. This is what one genetic genealogist called walking back.
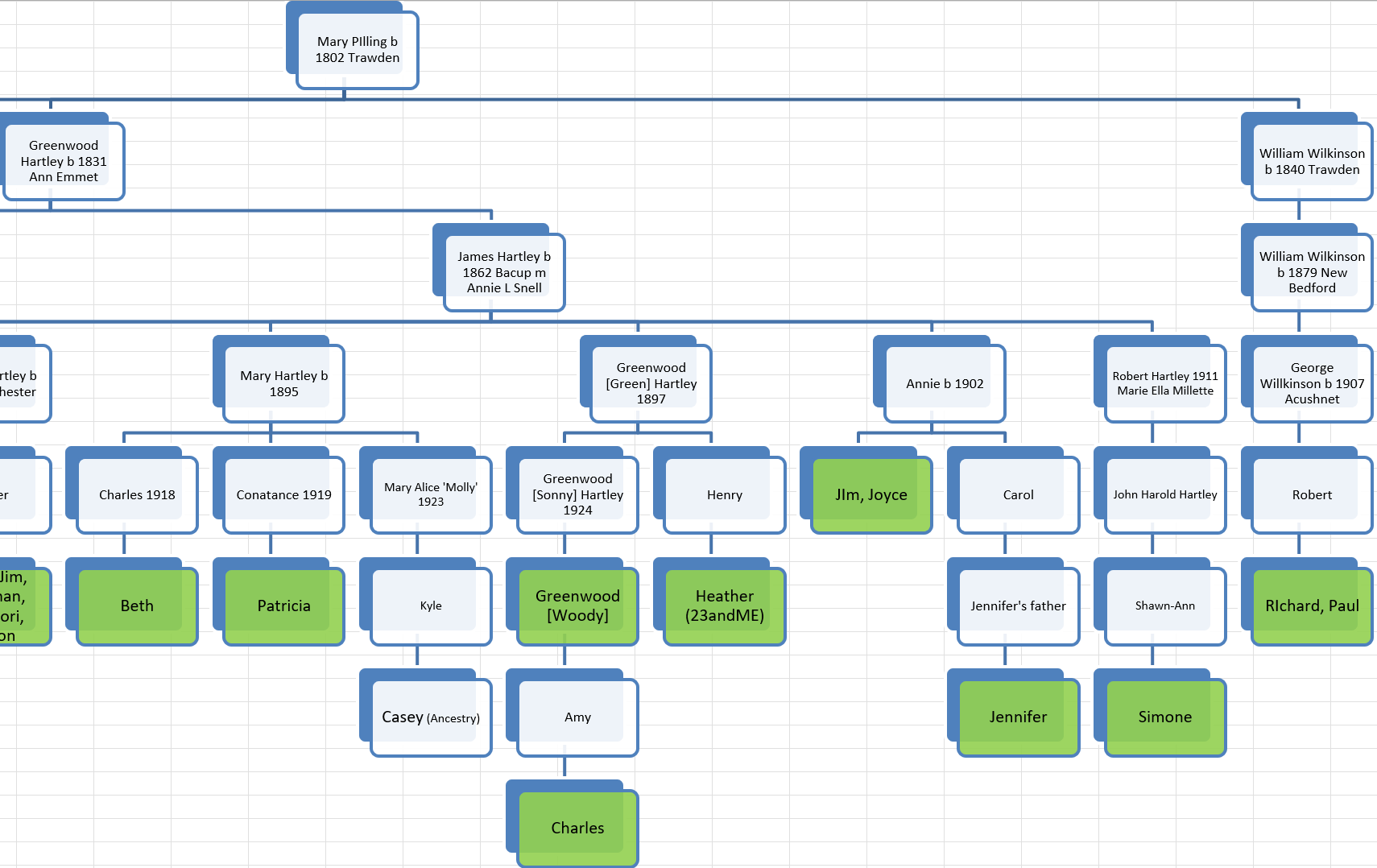
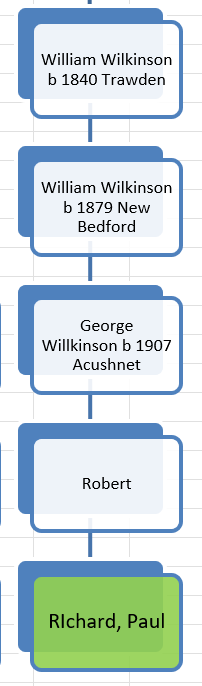
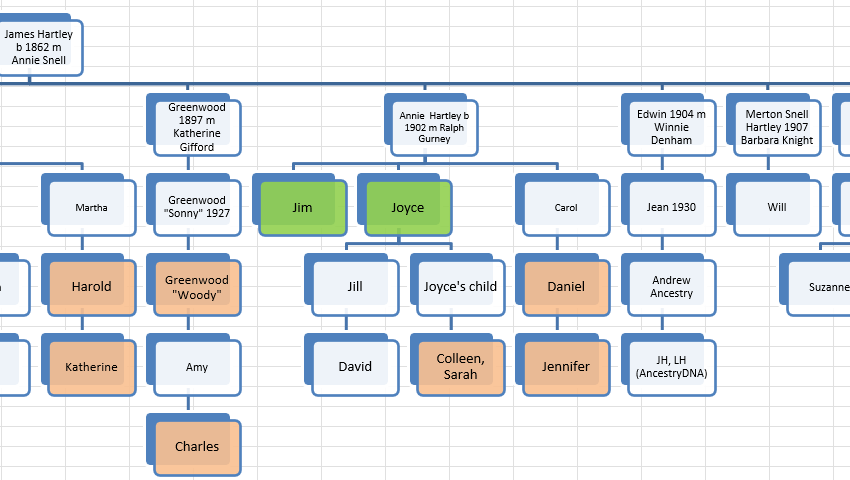
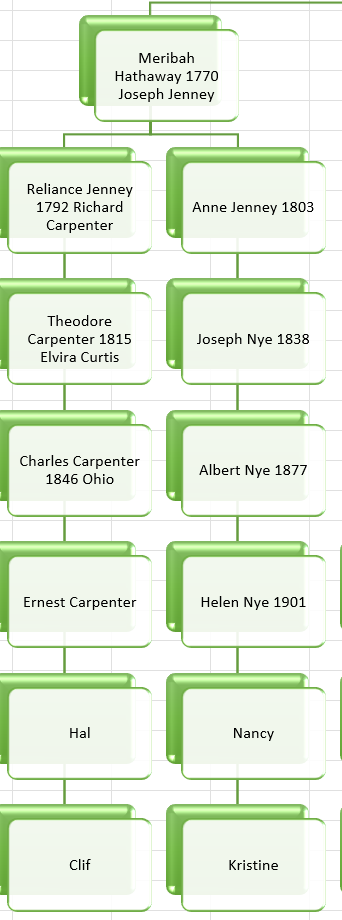
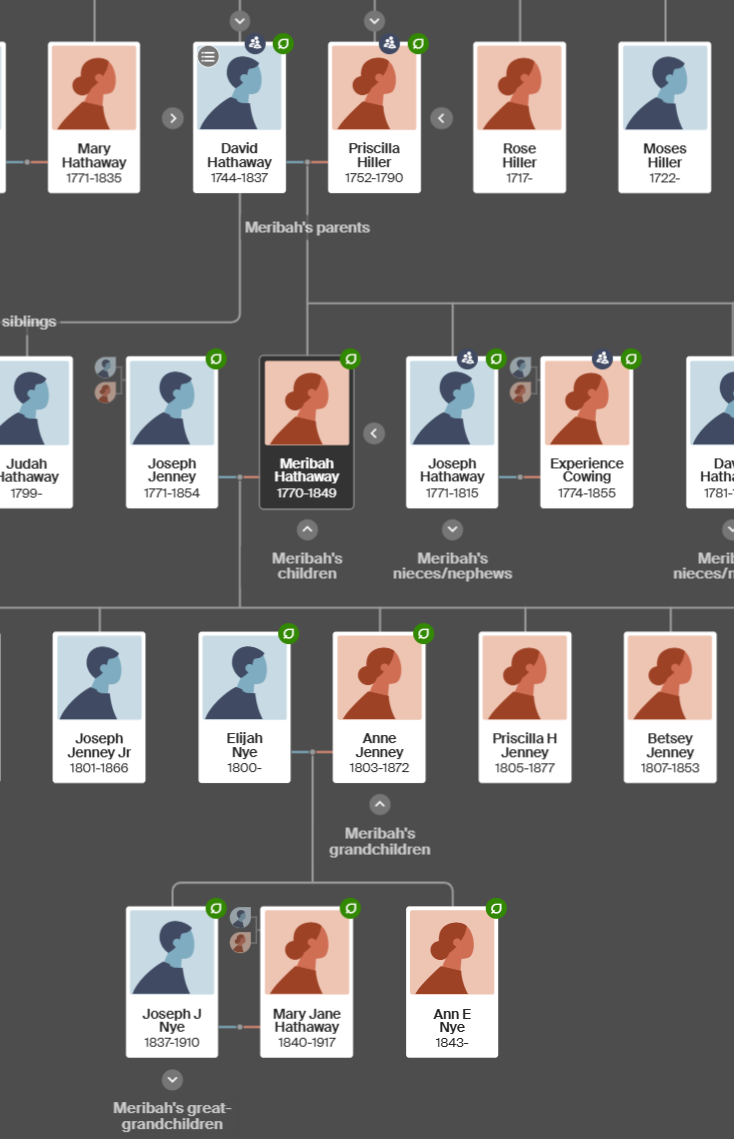
Here is the Meribah Hathaway Line from my Hathaway DNA Tree:
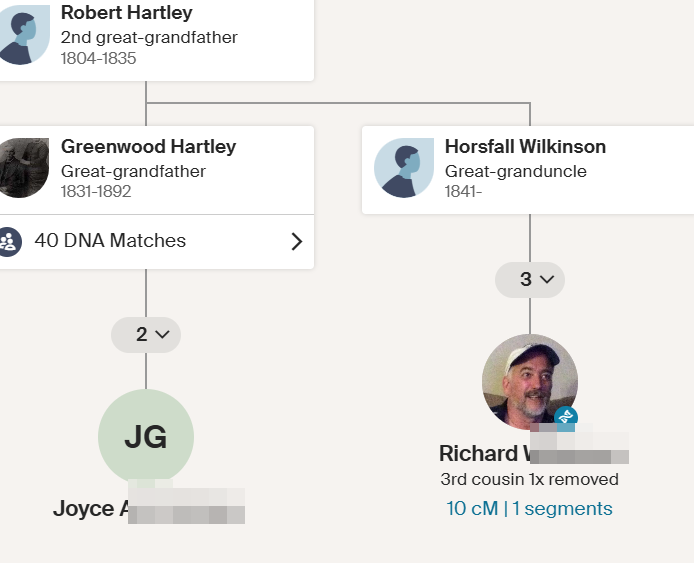
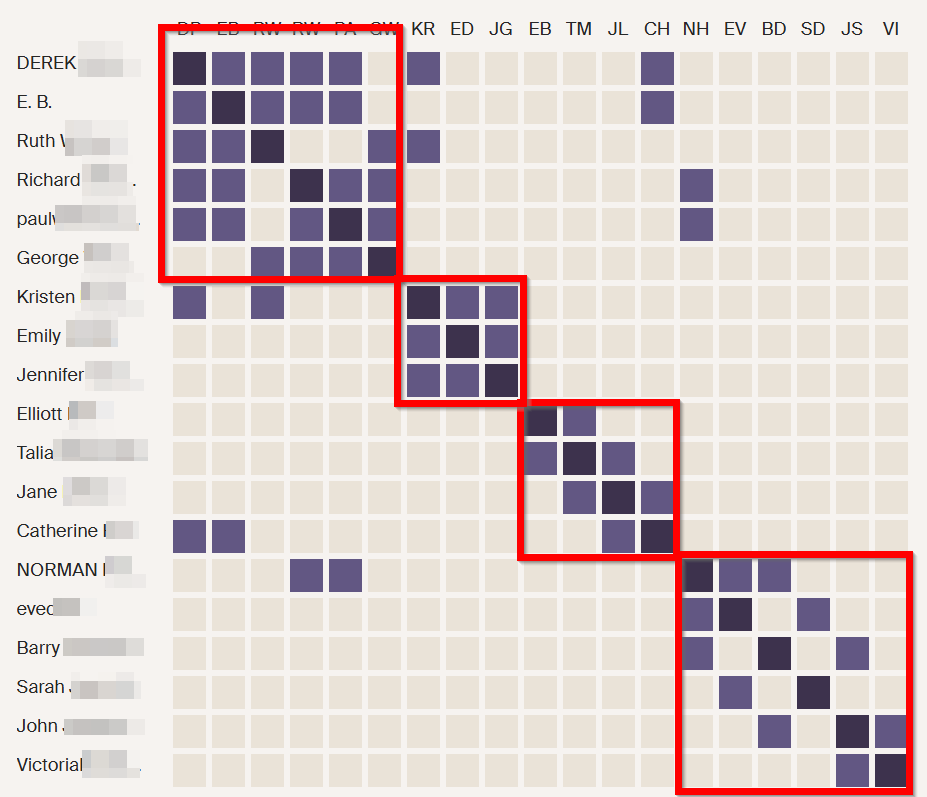
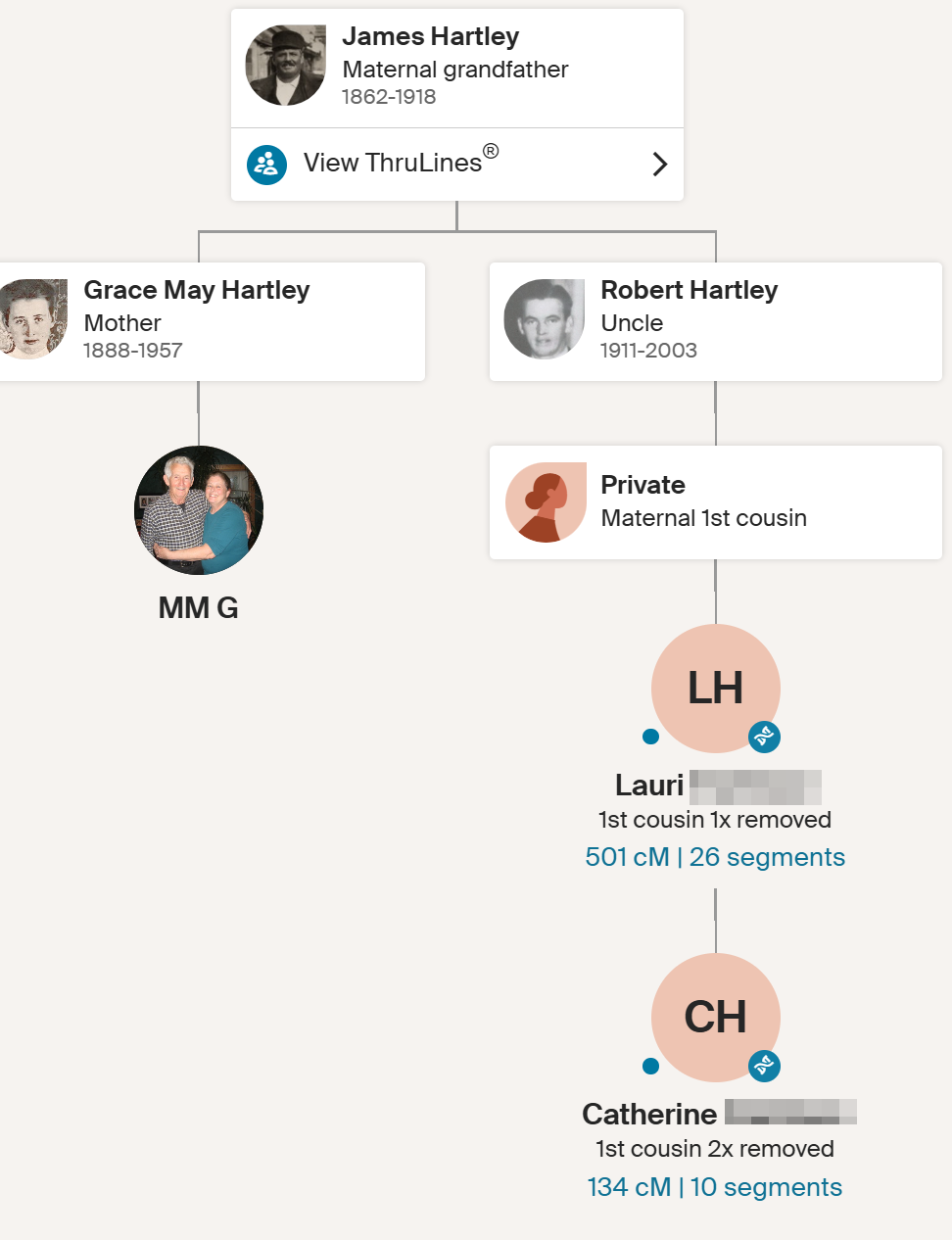
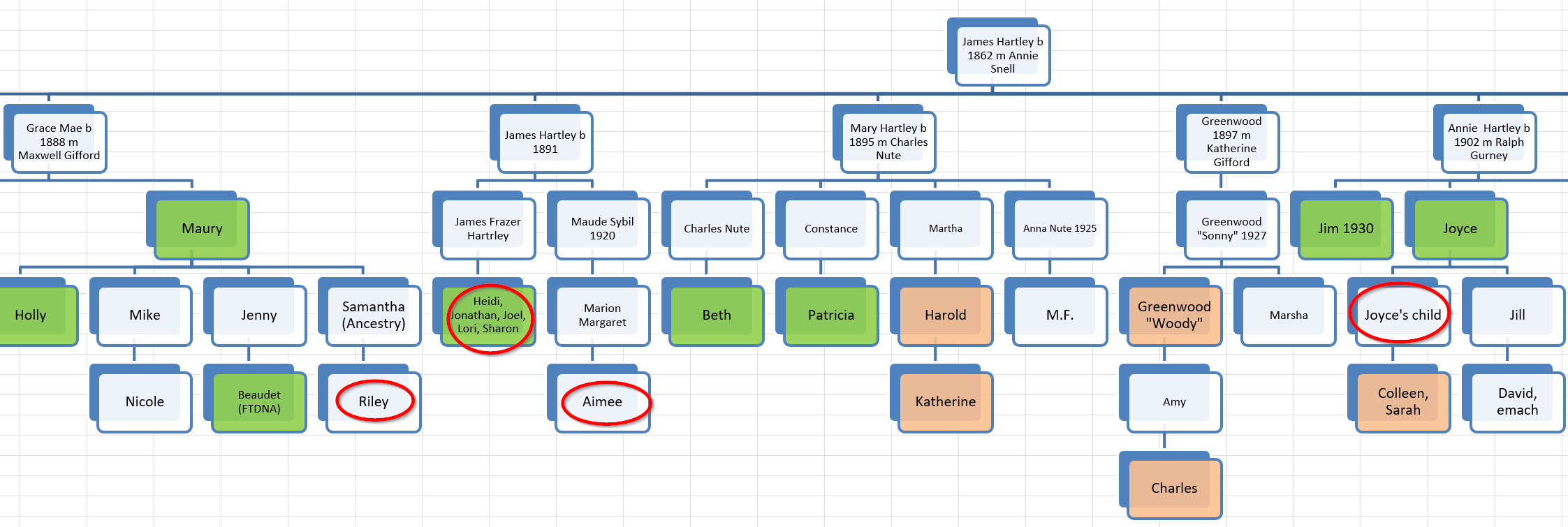
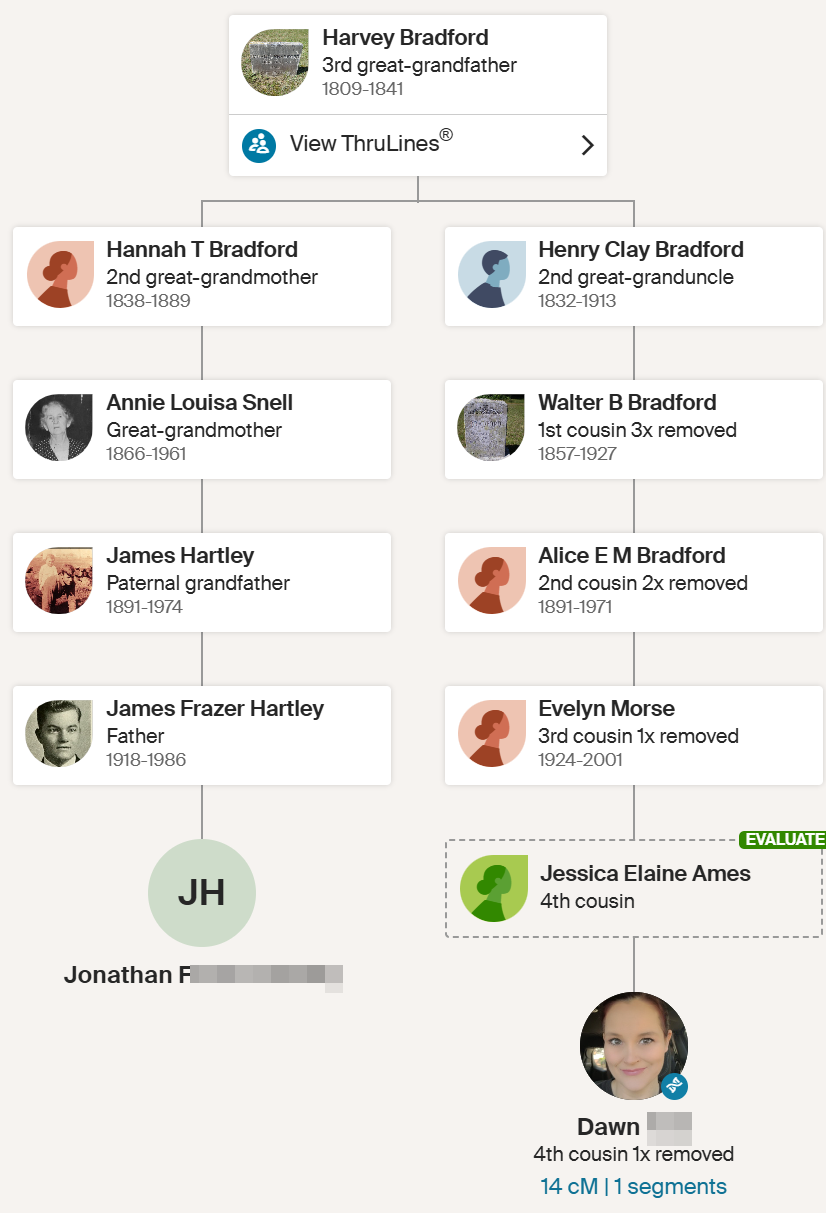
Jon’s ThruLines
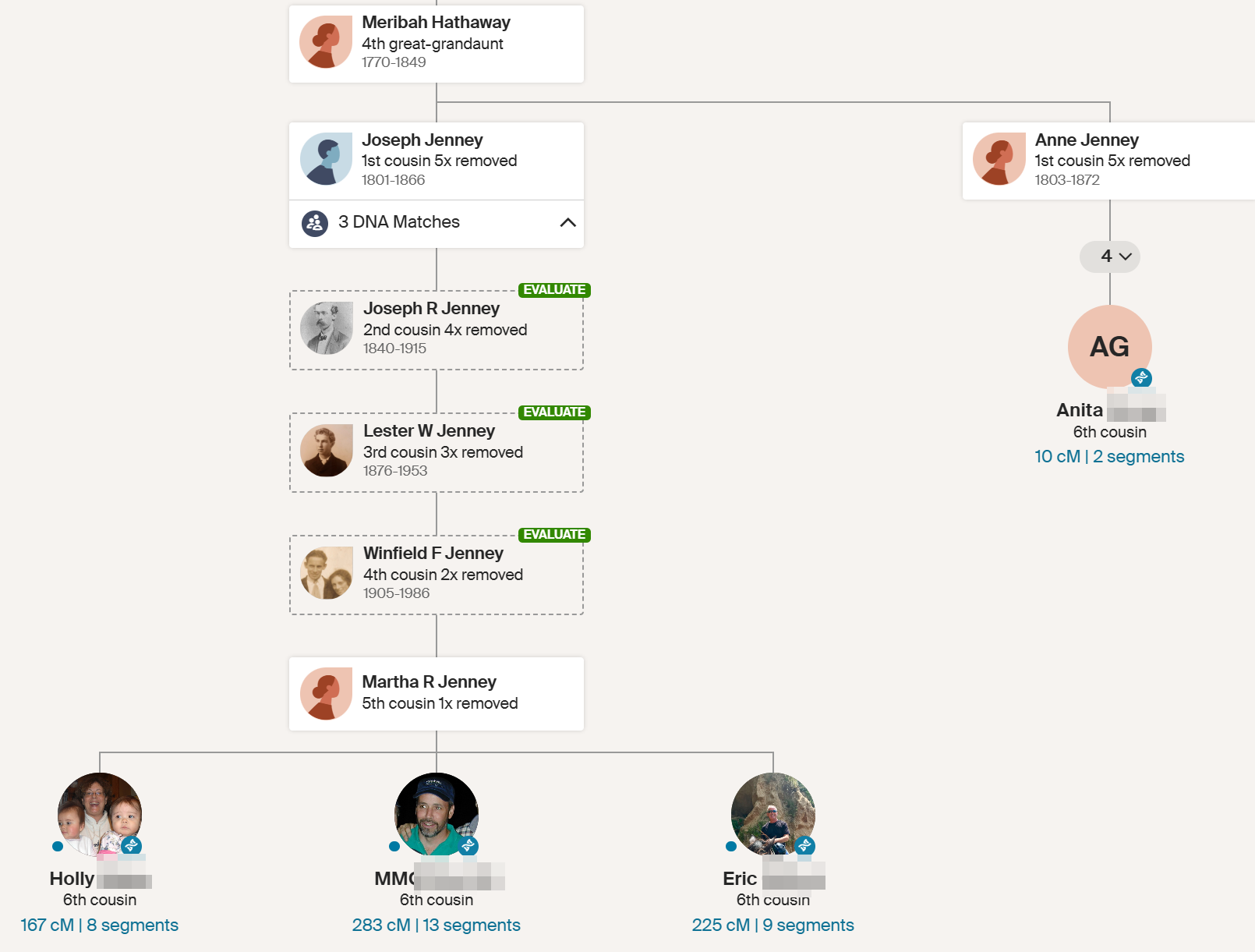
This gets a little confusing becuase Holly, MM, and Eric are also 2nd cousins on my Hartley side. Even more confusing, if I go back far enough we are again related on the Jenney side.
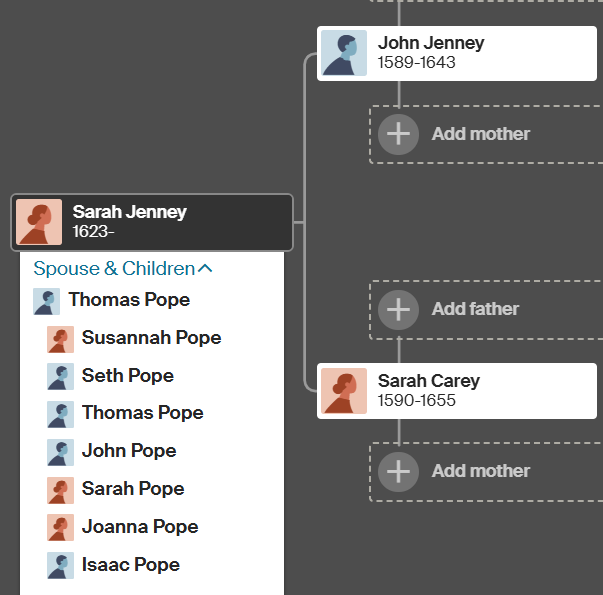
John Jenney is my 10th great-grandfather and I think that this couple would be another distant pair of common ancestors.
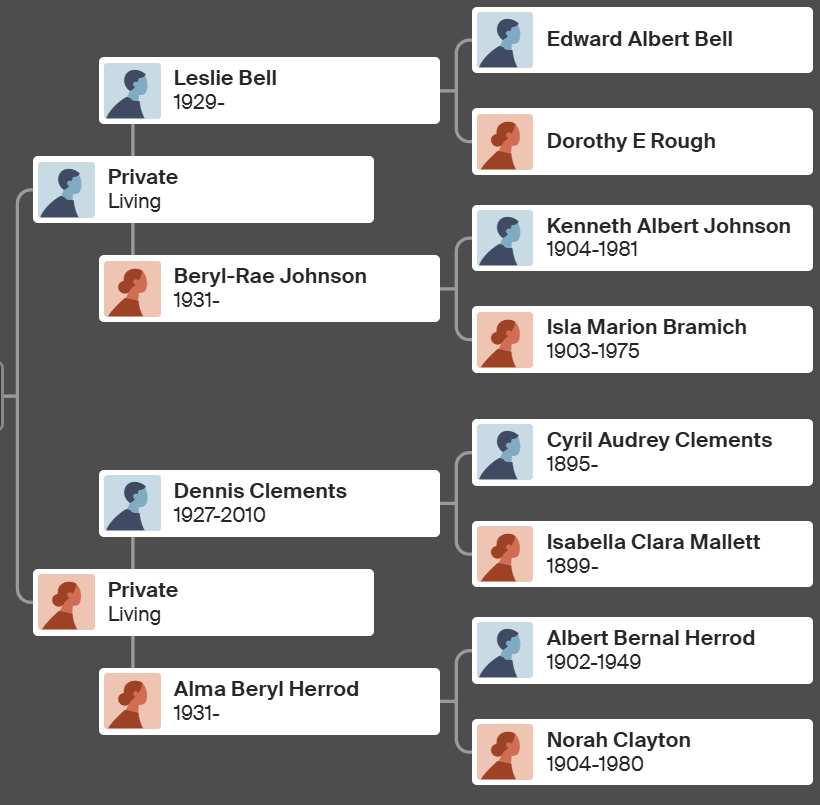
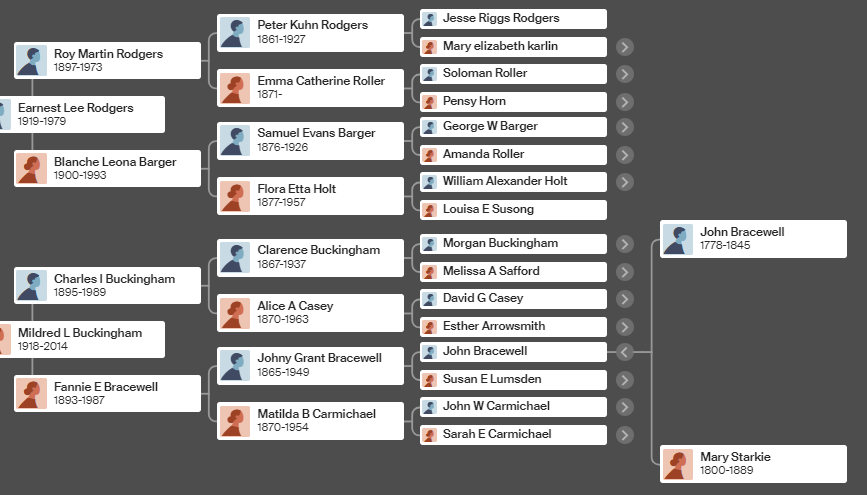
Anita’s Genealogy
Here is Anita’s tree at Ancestry:
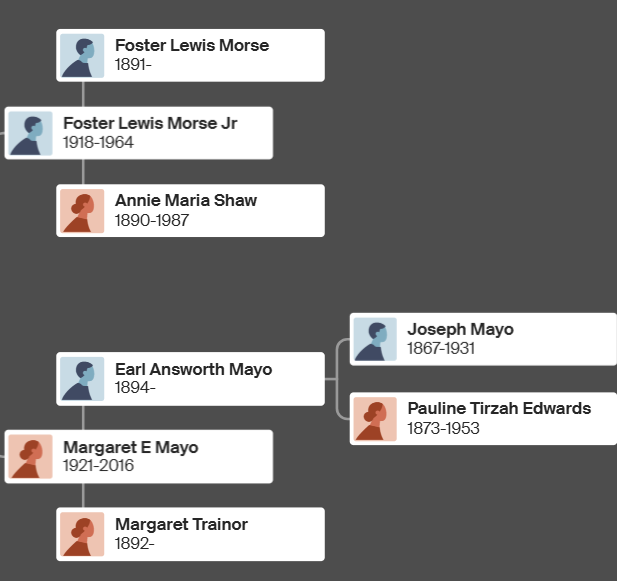
According to Ancestry, I should look at the Morse to Shaw Line. I can create a floating tree for Anita and then connect it to my tree assuming the genealogy looks good.
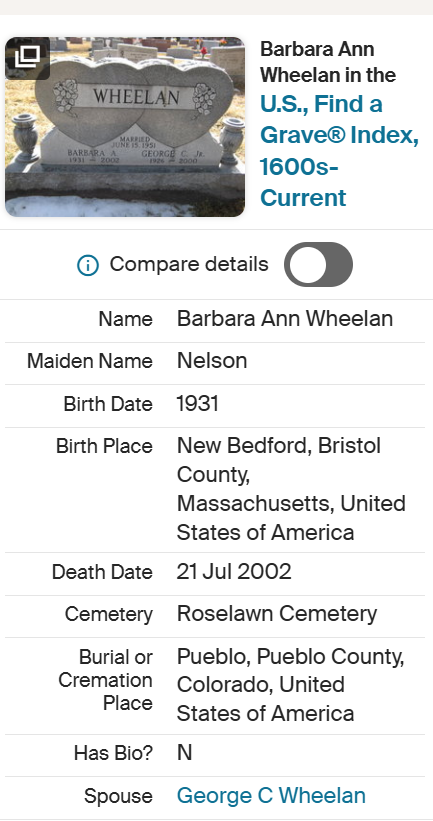
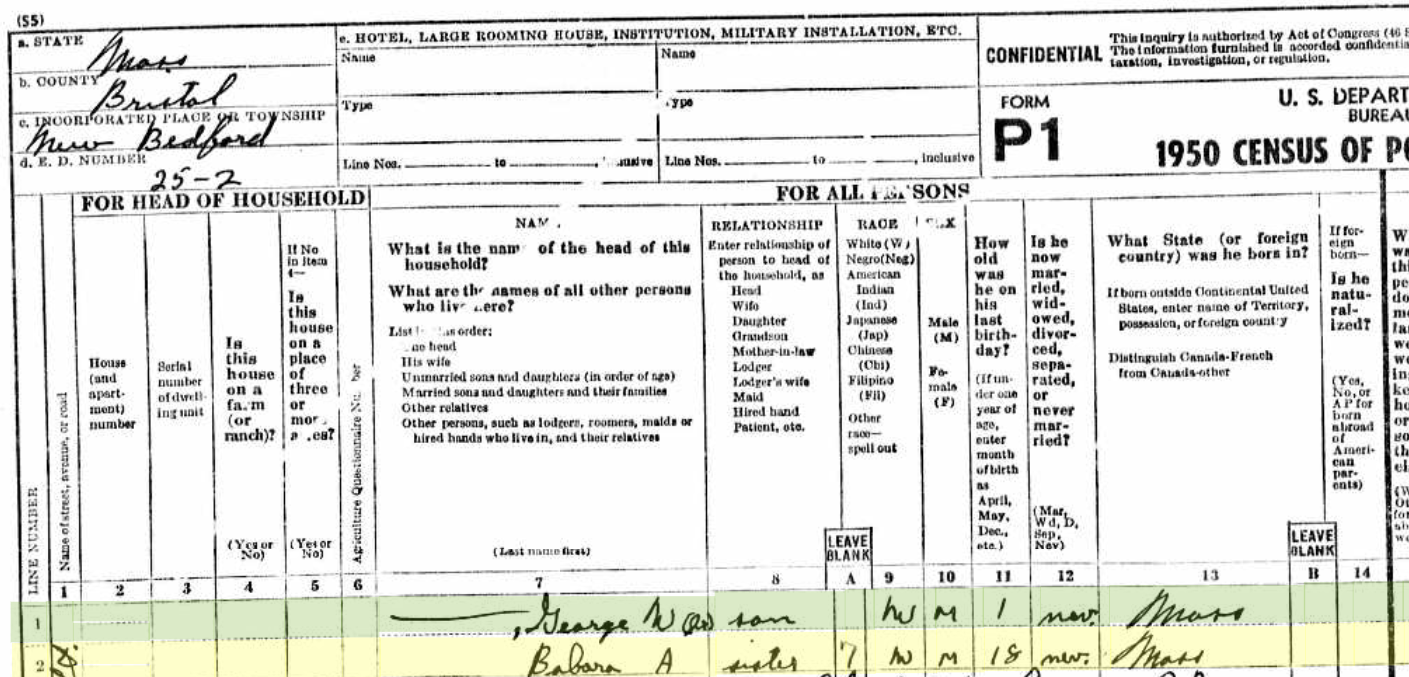
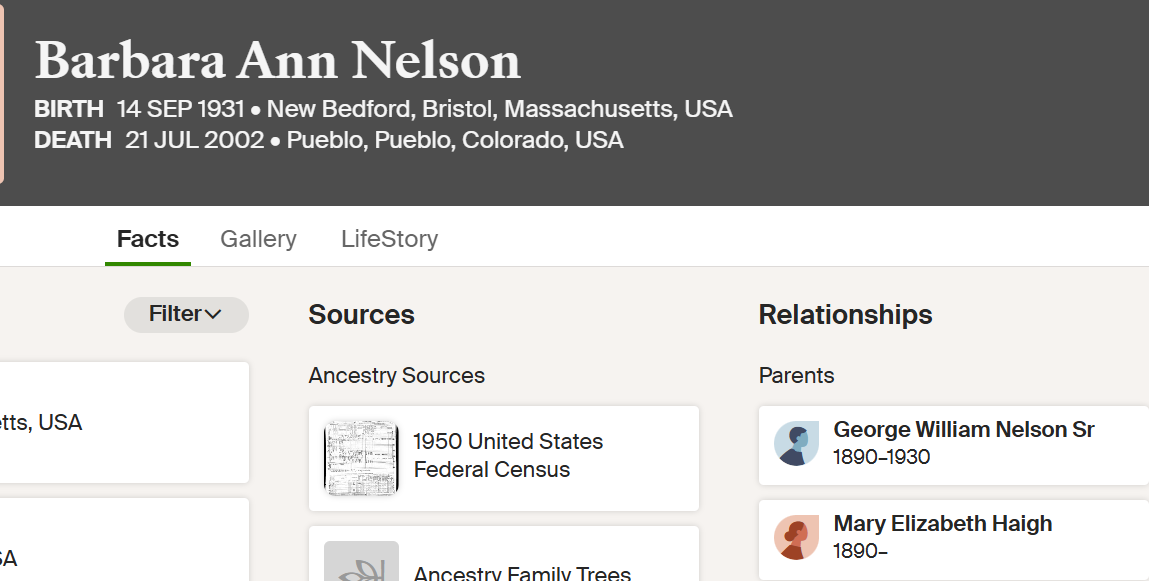
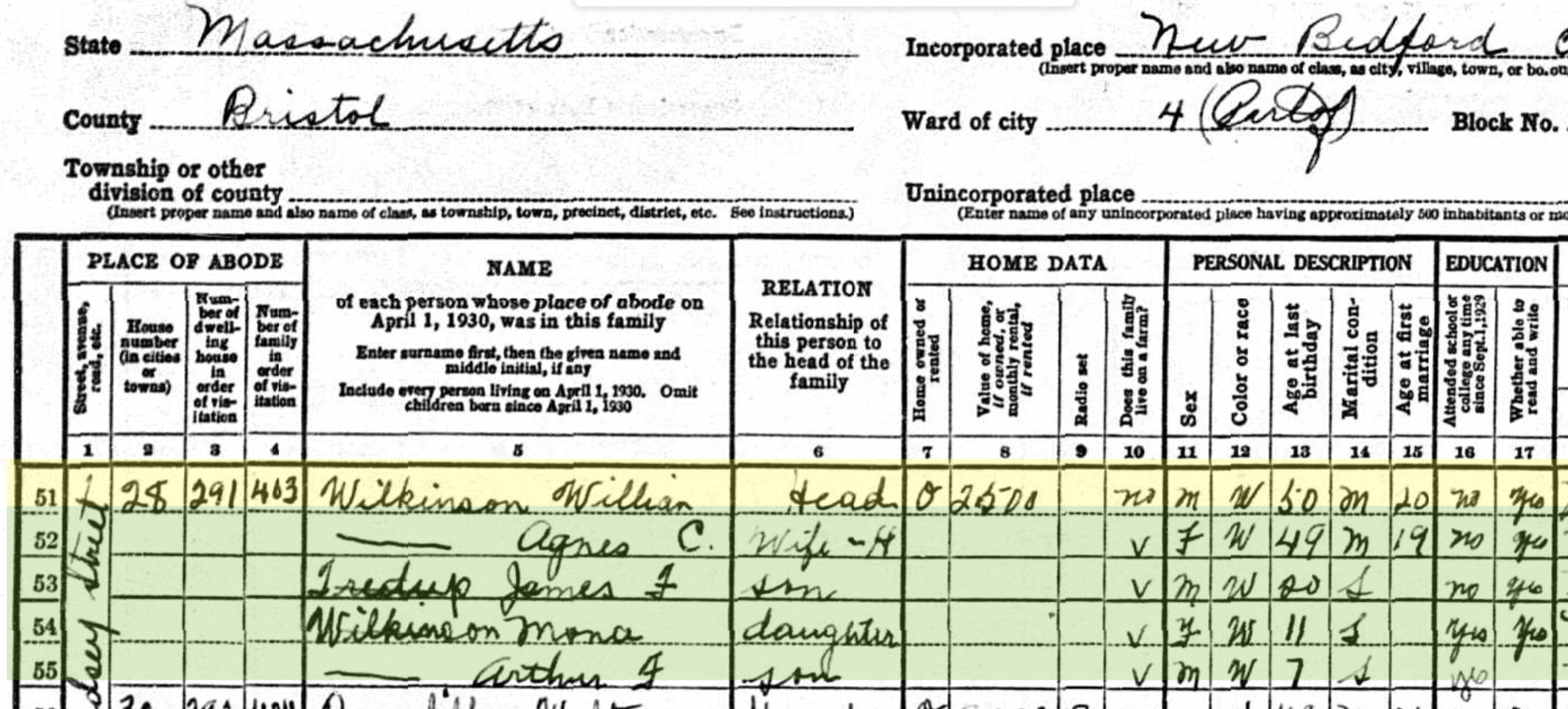
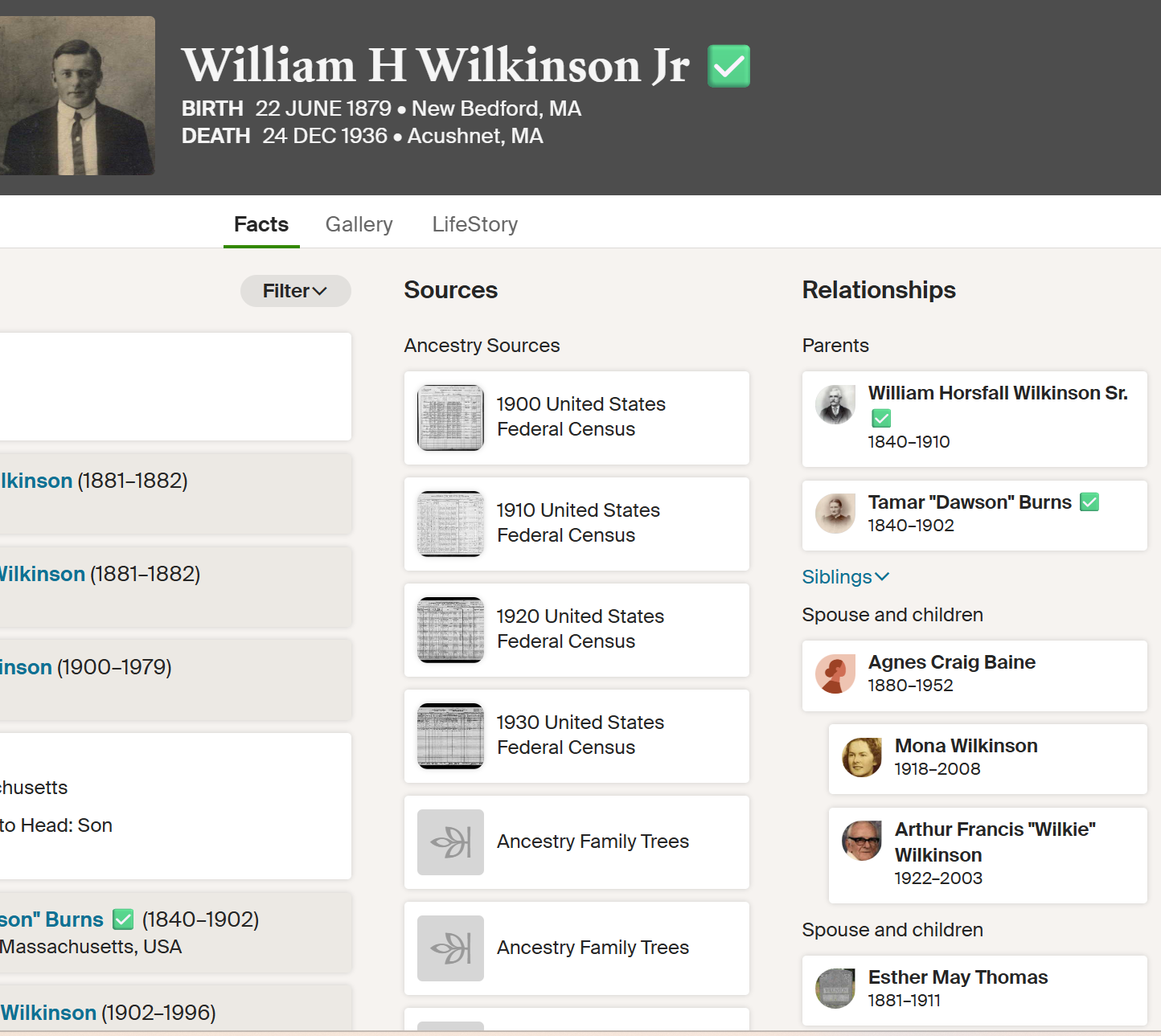
Anita already has found her dad in the 1920 Census:

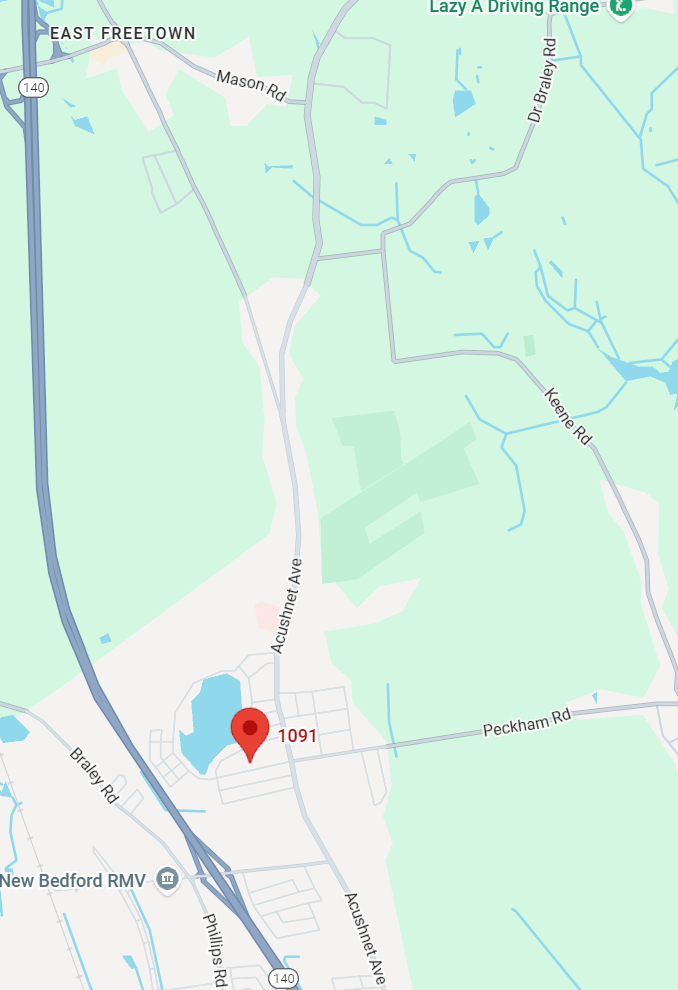
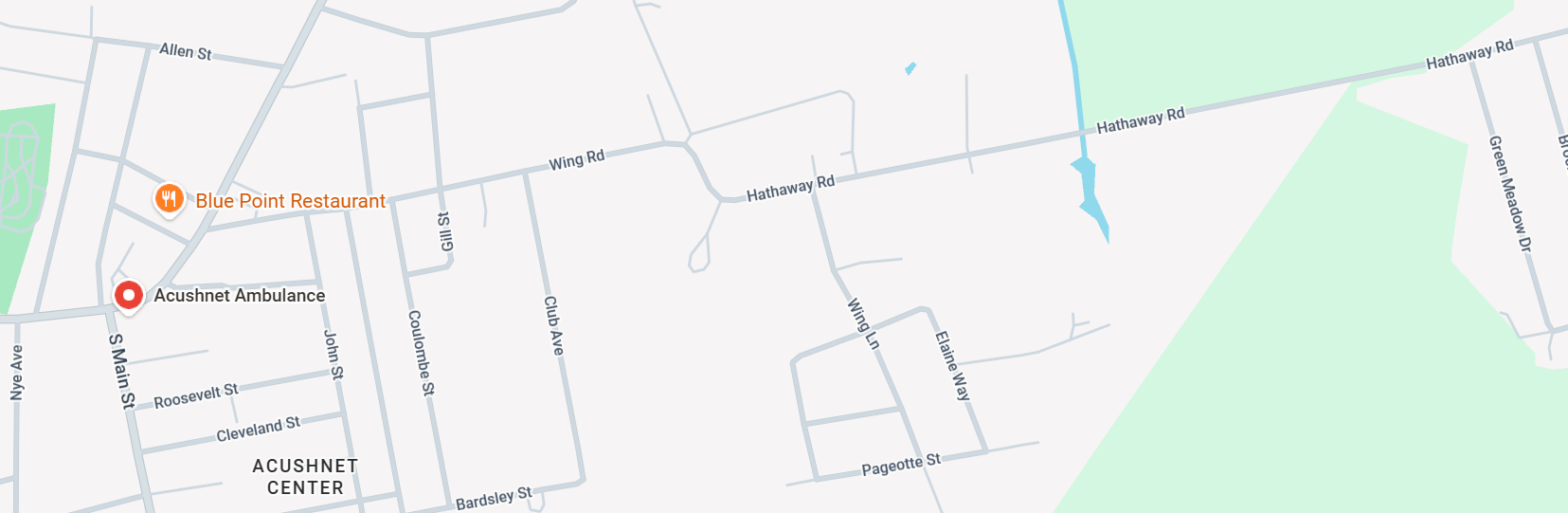
Foster L’s father was a farm laborer in 1920 and the family lived in Acushnet. Here is Wing Road, Acushnet, though Wing may have gone further down where Hathaway is now:
It would make sense to find a wedding record to confirm Anna’s maiden name.
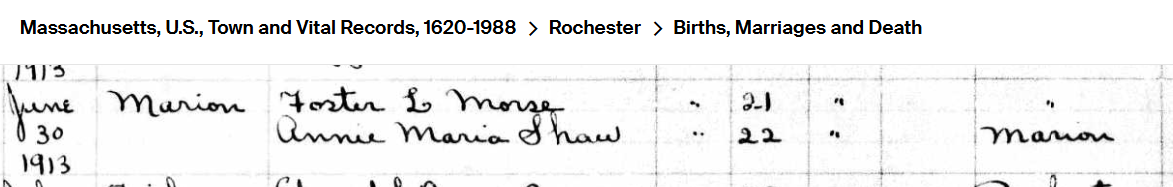
The couple get married in Rochester, MA in 1913 even though they live in Marion, MA.

Anna is born in North Carver.
Marion has a record of the marriage also, so perhaps the marriage did take place in Marion:
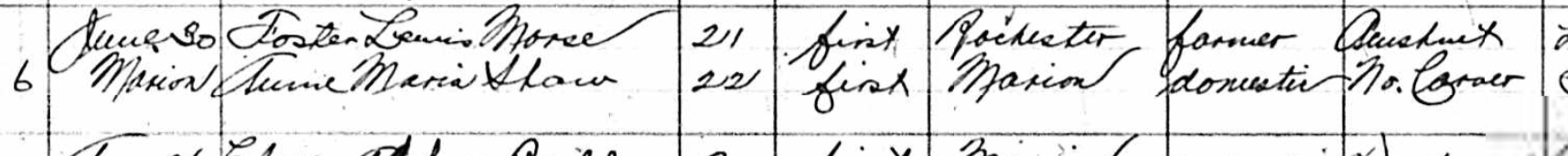
Annie was born in 1890 in Carver:
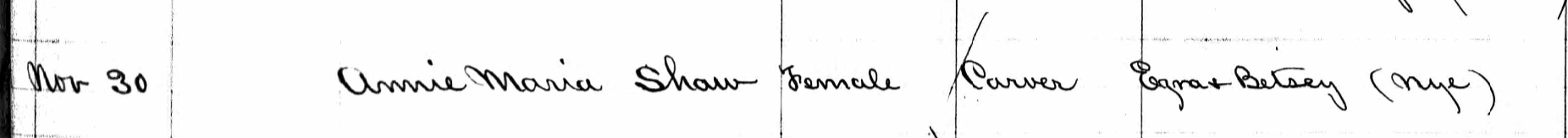
Annie’s mother was born in Mattapoisett:

Betsey Nye marries in Carver in 1890:

The marriage is said to be the first, but the fact that Betsey’s maiden name is given tells me otherwise:
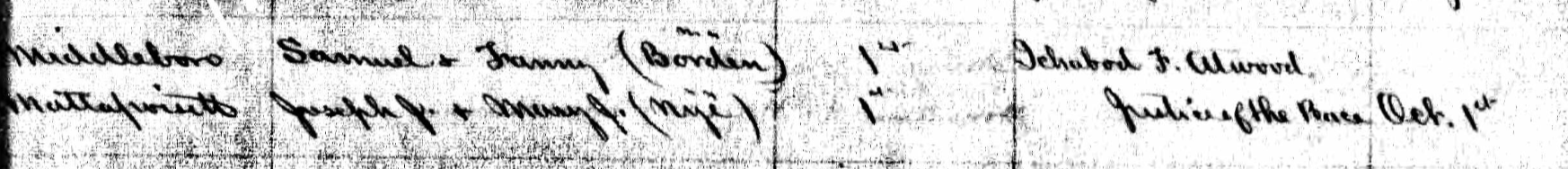
Here is Betsey’s death record:

This information from findagrave.com seems to clarify thing:
Aged 49 yrs. 9 mos. & 21 d’s
1st married to Manuel Gonsalves on Aug. 23, 1881 in Mattapoisett, MA.
2nd married to Ezra Shaw [son of Samuel Shaw and Fanny Borden] on Sept. 21, 1890 in Middleboro, MA. He died Aug. 15, 1893 in Carver, MA.
3rd married to Francis L. Nye on Sept. 9, 1899 in Mattapoisett, MA.
Here is what I have starting with Anita’s grandmother:
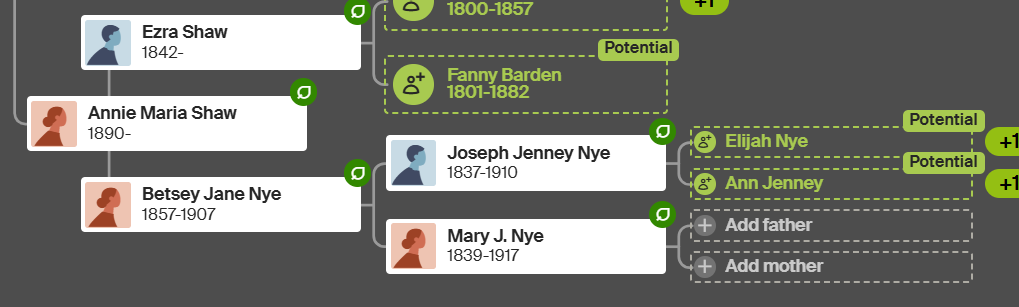
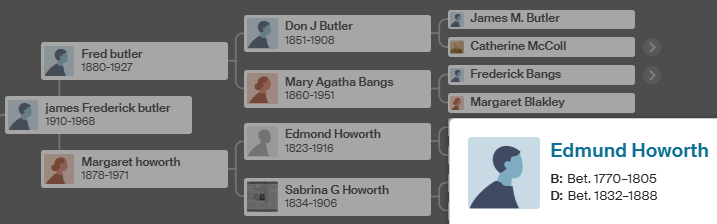
Another confusing point is that I am looking for the Hathaway line and Mary J Nye was a Hathaway. She was the daughter of Betsy Hathaway:
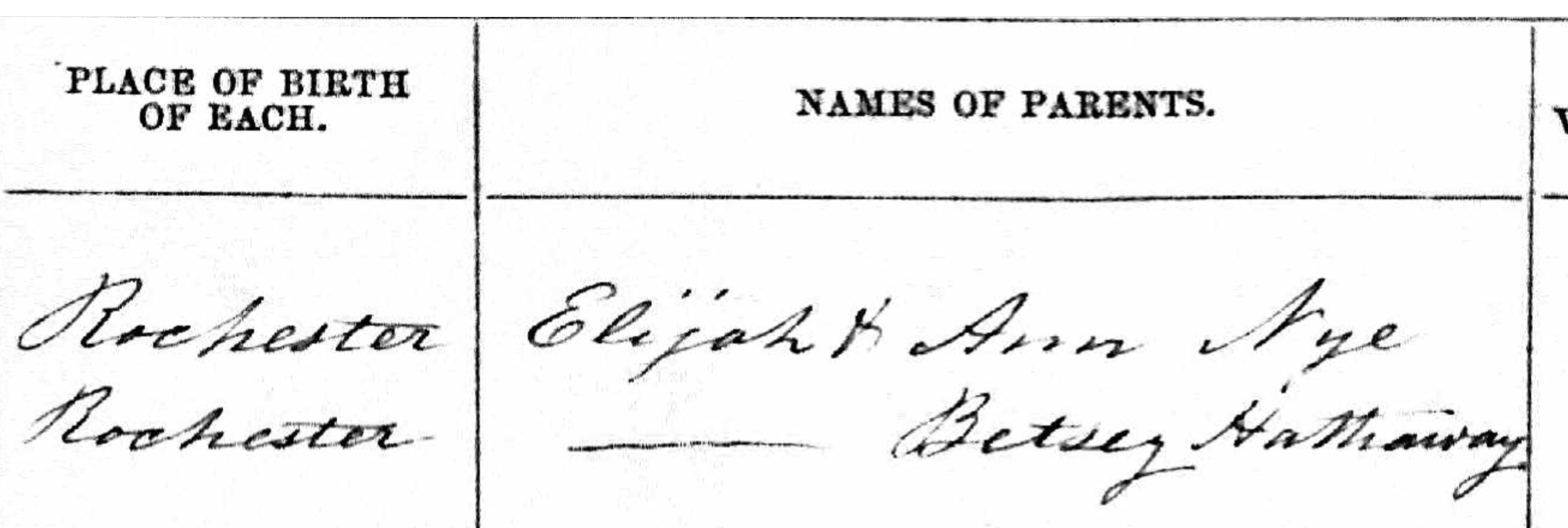
Mary did not name a father on the marriage record in Mattapoisett in 1857. Joseph Nye was listed as a mariner at the time of marriage. This is the page for Hathaway births in Rochester:
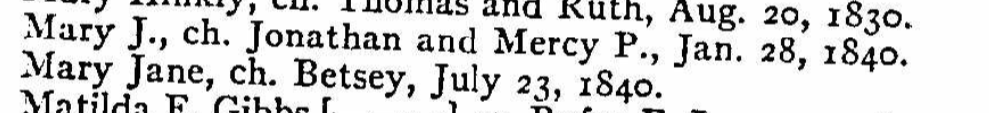
I wonder who Betsey’s parents were and what happened to her?
Mary Jane’s death record gives little information:

As far as I know, I am not as closely related to the Mattapoisett Hathaways. My Hathaways lived in Wareham.
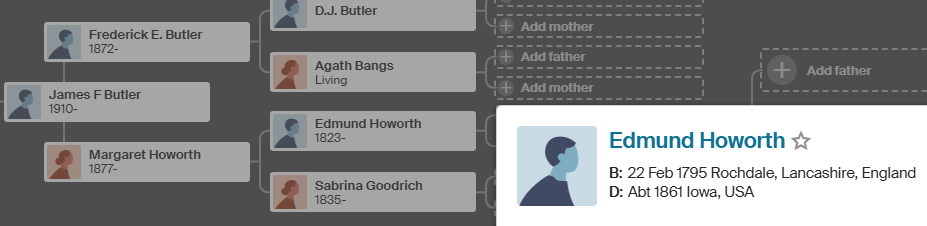
Connecting Joseph Nye to Mother Anne Jenney
This would connect my floating tree to my Ancestry Tree. Here is Joseph’s birth:

Here is Anne Jenney from my Tree:
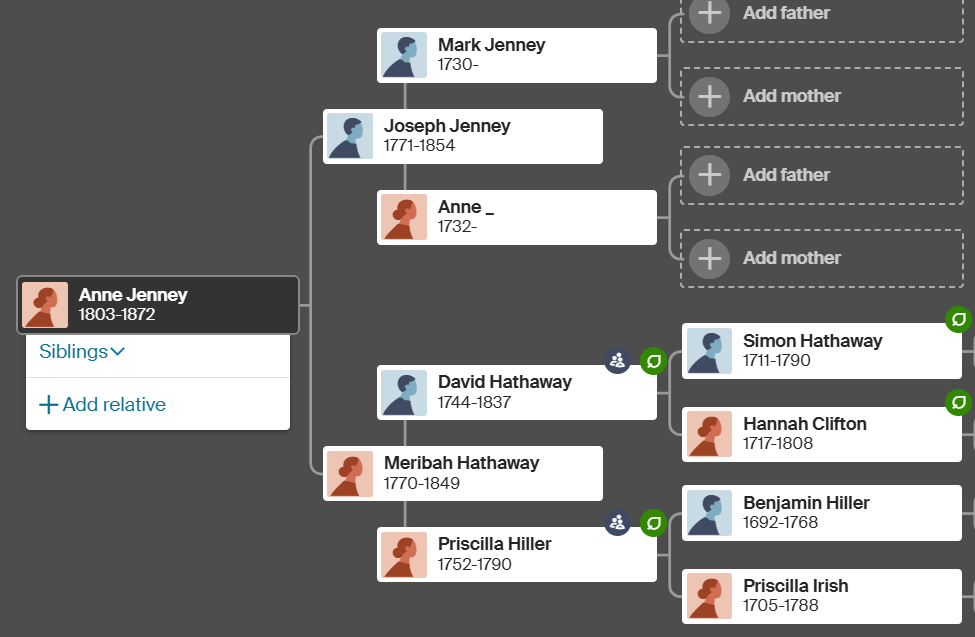
I am pretty sure it is OK to connect the two, but I will look for some more evidence. This 1872 death record for Mattapoisett is enough to convince me:


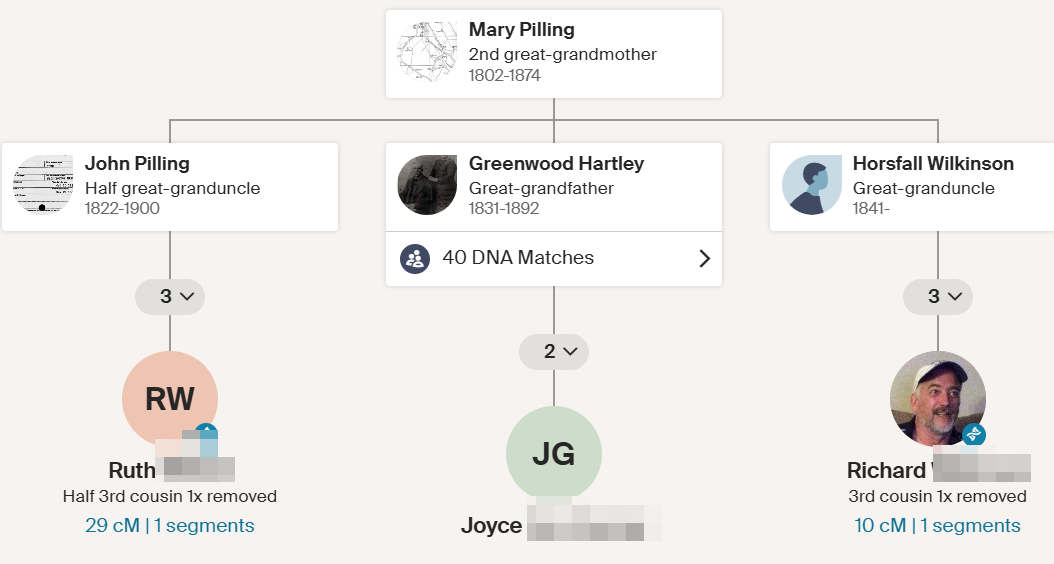
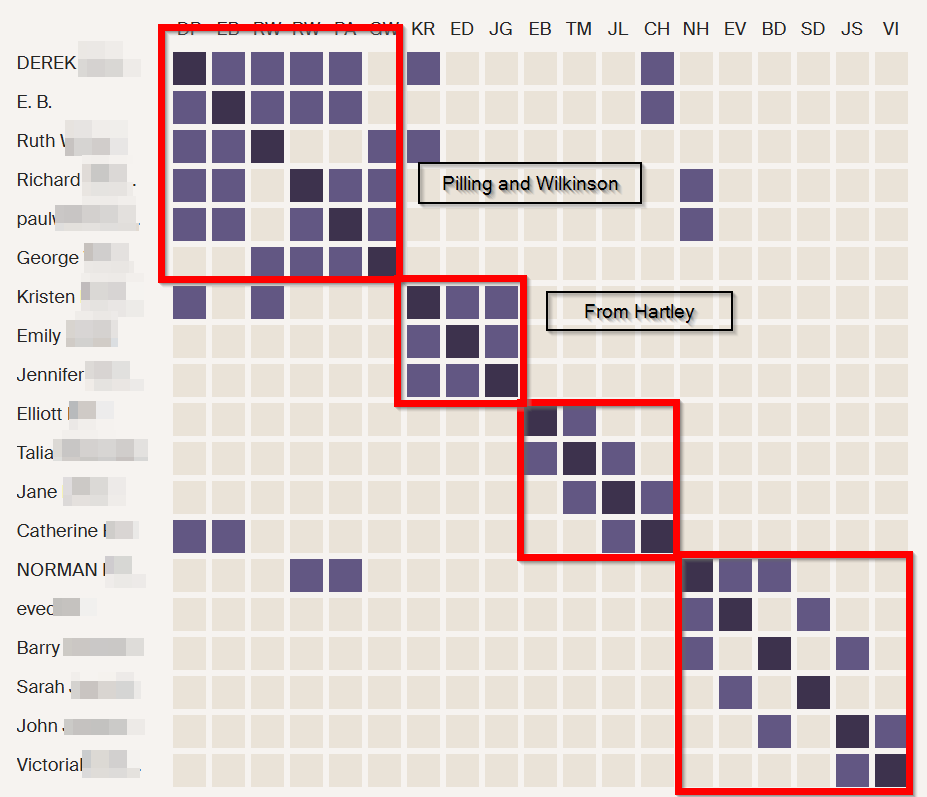
The Hathaway DNA Tree
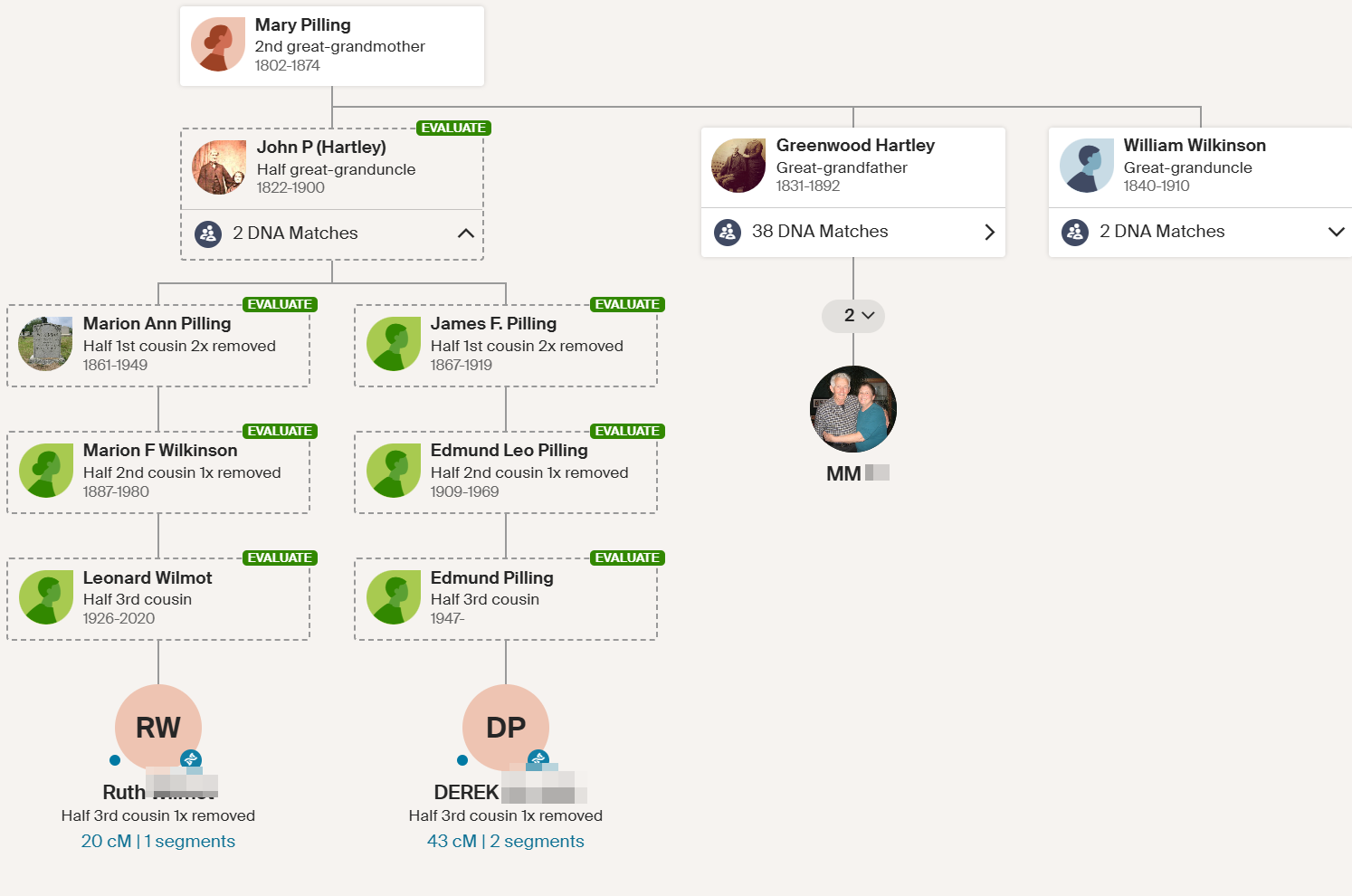
Here is my Ancestry Tree in vertical view:
According to this view, Mary Jane has her first child when she was 17:
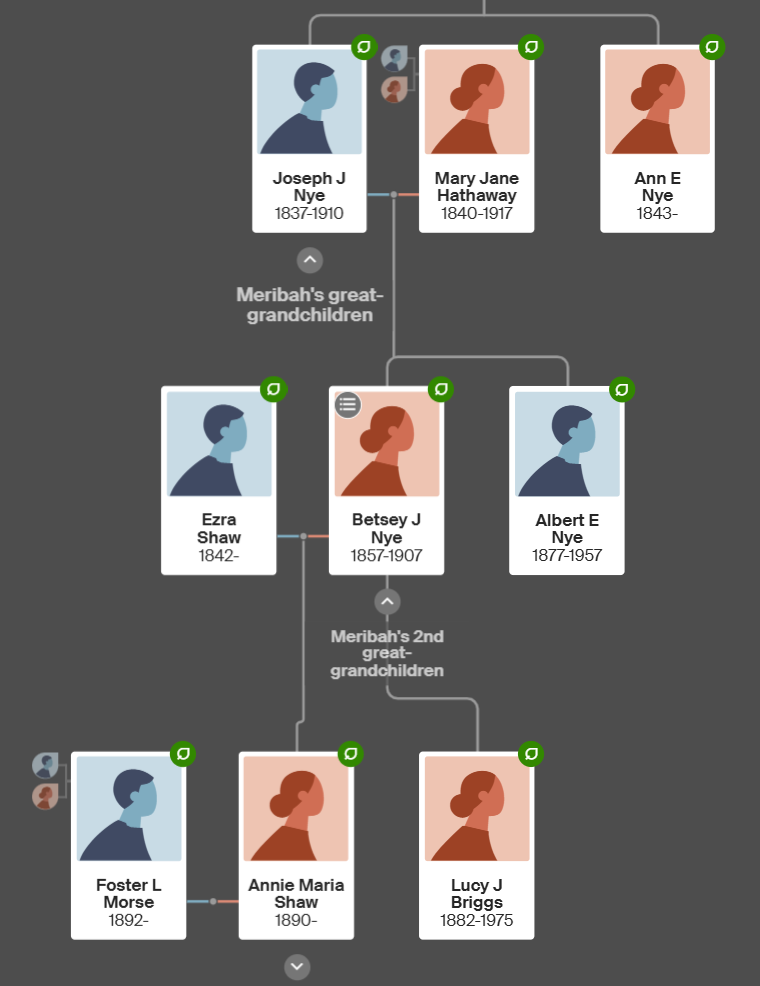
Technically, Mary Jane was 16 when she married:

Here is part of my Hathaway DNA Tree showing that Anita and I are 6th cousins:
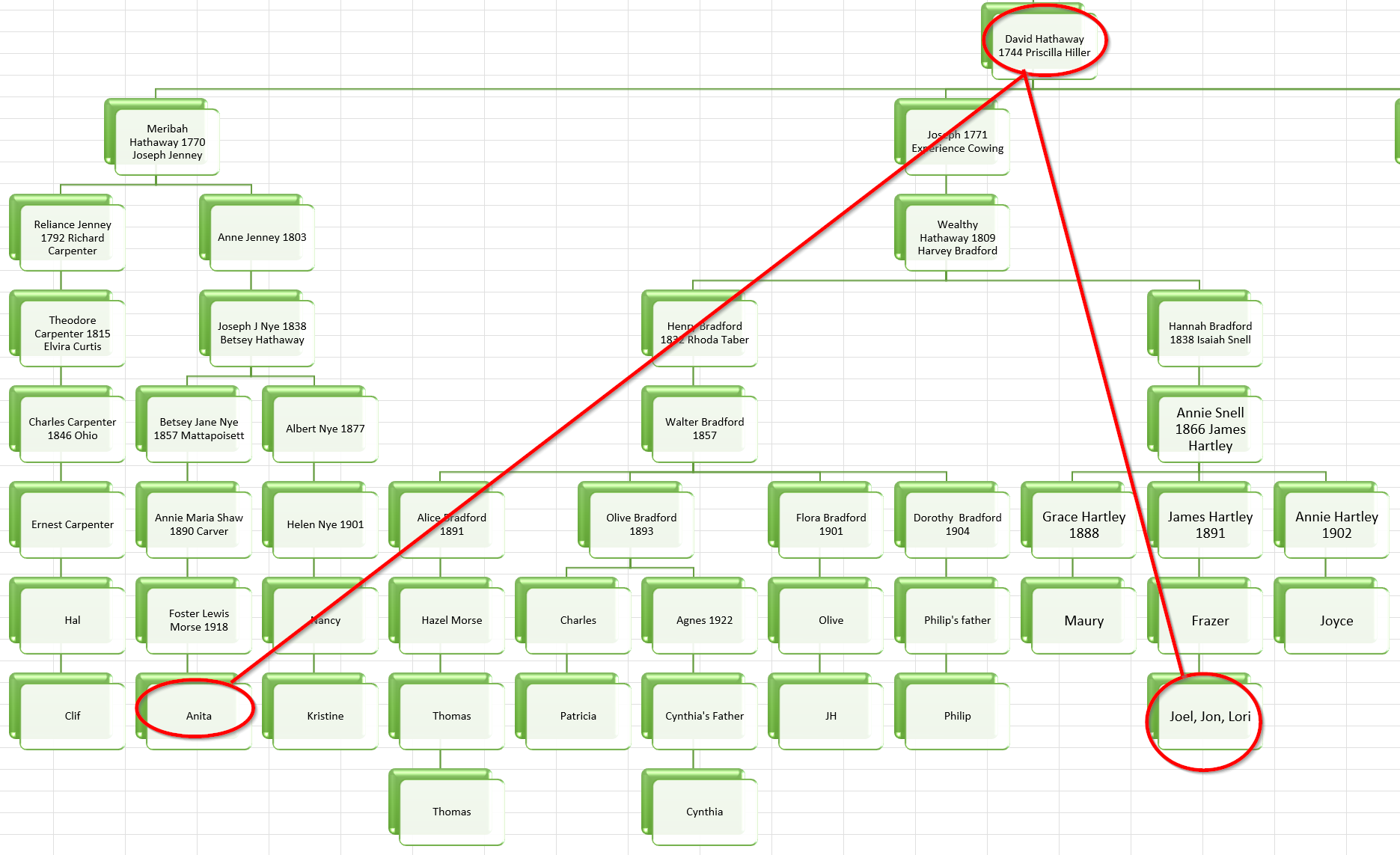
Summary and Conclusions
- This was an interesting excercise going back to Mattapoisett. A single parent child marries young, has a child young and her husband is a mariner. Hopefully she had otherh family and/or community support
- Anita and I have quite a bit in common. We both had parents born in 1918.
- We descend from siblings born a year apart: Meribah Hathaway in 1770 and Joseph in 1771 – both before the Revolutionary War.
- Both Anita’s family and my family seem to have stayed in SE Massachusetts.
- These common ancestor excercises are good in that they do not take too long and they improve my understanding of a family line’s genealogy as well as local history.