I have written many Blogs on raw DNA phasing with my siblings and my mother. I have done this phasing using a Whit Athby paper and MS Access. I had my last sibling tested this past Summer, so thought I would see how his phasing would work using this method. The goal of this phasing would be to get four files of data representing the DNA from my four grandparents. I have four such files already, but they were created by M MacNeill a while ago and he didn’t have all my siblings’ data at the time. I would like to learn how to upload these files on my own.
Jim’s Raw DNA
Jim was my last brother to be tested. He was tested at FTDNA as that was the kit I had at the time. The first step is to find Jim’s DNA download from FTDNA and extract it. However, before I do that, I need to know what build to download. As I look at my old blogs, it appears that I was working in Build 37. Gedmatch has historically used Build 36. However, Gedmatch is being migrated to Genesis. Here is a comment I found on Facebook:
All Genesis tools natively work in B37 *meaning that all matching is done based on B37), but we decided to map all of the B37 positions to B36 and B38 when printing out segment start/end positions, with the choice given to the user which to display.
We will begin to migrate this to other tools as soon as we can. I hope you find it useful.
Build 37 DNA
All this to say that I want Build 37. I assume that I used Build 36 for Gedmatch, so I’ll do a new download for Jim:

I chose Build 37 Raw Data Concatenated. Unfortunately, my computer wants me to find an app to extract this file.

In the past, I have used Notepad, so I’ll try that. The gz file is about 6.4 MB. I can see Notepad was the wrong thing to open this with:

So I guess I need Winzip. I downloaded that and then opened Jim’s file. It opened as a csv file, but I saved it as an Excel File as that is what I will be using in Access. Jim has double A DNA:

Actually the DNA at the first position of his tested Chromosome was AA. He got an A from his dad and an A from his mom. Jim has a lot of DNA

This shows that Jim has 720,450 tested DNA positions. That is pretty good. However, there are some positions that don’t have results indicated by –. Between my mother, me and my five siblings there are about 4 million autosomal results to look at.
One thing that I notice that is different from this AncestryDNA file:

AncestryDNA has a separate column for allele 1 and allele 2. That would be better for me as I am trying to separate these alleles out.

This looks better. However, when I try to import this into Access, I get this error:

My guess is that Access does not like the dashes where there are no results. So I’ll take out every dash in Jim’s DNA results. That was close to 60,000 dashes. I tried that, but I still got the error. One on-line suggestion was to compact and repair the database. That seemed to work, but there was this problem:

I didn’t realize that there was a new header at line 702542. That imported like this:

Also for the AncestryDNA files, the X Chromosome shows as Chromosome 23, which should work better. My import to Access took out the ‘X’. After I removed the internal header and changed the X Chromosome to 23, I imported Jim’s raw DNA with no problems.
Giving Jim some Maternal DNA
Now Jim’s DNA is in shape for doing something with it. The next step is pretty simple. Every time my mom has two alleles that are the same, we know that allele is maternal for Jim. I originally tested my mom at FTDNA, so it would make sense to download her DNA from there.
Importing Mom’s DNA to MS Access
I already learned a few things from downloading JIm’s DNA from FTDNA. I used the same steps for my mom, except that I didn’t delete the dashes to see if that would make a difference. That gave me an error, so I deleted the dashes. Now I am in business.

My mom has 711,398 locations tested at FTDNA. This is a bit less than Jim’s 720,450 tested locations.
Next, I want to see what happens if I compare Mom’s ID’s with Jim’s ID’s:

Here at Access I have an equal join between the RSID fields of both tables. That results in 709,632 positions that Jim and Mom have in common. When I compare the positions between the two, I get 712,452. That is more than my mom had, so that doesn’t make sense. Actually, I shouldn’t be comparing by position, because those are positions along each of the 23 chromosomes. There may be repeats. That is good to know.
Where is Mom Homozygous?
If Mom’s Allele #1 is the same as Allele #2, that is called homozygous. I’ll perform this simple query on Mom:

I asked Access to show my where my Mom’s Allele 2 is the same as Allele 1:

Mom has that in 500,995 places. However, next, I need to get rid of the blanks:

I added Is Not Null to the criteria on the Result Column:

That gets me down to 496,136 homozygous positions. That means that more than 2/3 or almost 70% of Mom’s results are homozygous. Those are the alleles that will be Jim’s maternal alleles.
Where is Jim Homozygous?
Where Mom is homozygous, we’ll add a Mom allele to JIm. But first, where Jim is homozygous, we will add a Mom and Dad allele. I created a simple query in Access:

I’m creating two new columns for Jim. One will give me the alleles that Jim got from his Dad and the other will give me the alleles that Jim got from his Mom. In the criteria row I have that Jim’s allele 1 must equal Jim’s allele 2. When that happens, put in Jim’s allele 1 into the column. That gives me this:

That gives me over 500,000 rows of paternal and maternal alleles for Jim. However, I do have blanks. When I filter the blanks out, I get 491759 rows. That is a fast way to get almost 1 million alleles for Jim. Next, I’ll make a table of this query in Access. When I do this, I notice that Access has changed my query:

Access liked this better as it was simpler. I would think that JImallele2 does not have to be there twice, so I took one out and got the same result:

Access is trying to teach me to make better queries.
Adding Maternal Alleles from Mom
Here is a summary of where we are for Jim:

Just by assigning Jim’s own homozygoius alleles to his paternal and maternal sides, he is now 71% phased. I also see that mom had 496,136 homozygous alleles. These need to be added to Jim’s homozygous results. However, I want to be careful:
- When I add Mom’s alleles, I don’t want to erase the ones I already gave to Jim
- There may be homozygous alleles that mom had that Jim didn’t even test for. These could be added to Jim as bonus alleles.
- In adding mom’s homozygous alleles to Jim’s list, we also have to add in where the position of those alleles are on the Chromosome and the RSID.
First, I note that mom has 496,136 homozygous alleles. This is more than Jim’s homozygous alleles.
First, I’ll create a query for Mom’s homozygous alleles.

Here I want there to be a non-blank result and I want Mom’s allele 1 to be the same as allele2.
Next, I’ll check to see how many of Jim’s homozygous alleles are the same as mom’s homozygous alleles.

I’ll do this by an equal join on the RSID which is a unique identifier. Here is what I get from this query:

However, there are still blanks there. I had trouble getting rid of the blanks, but I can temporarily get rid of them by filtering the results.
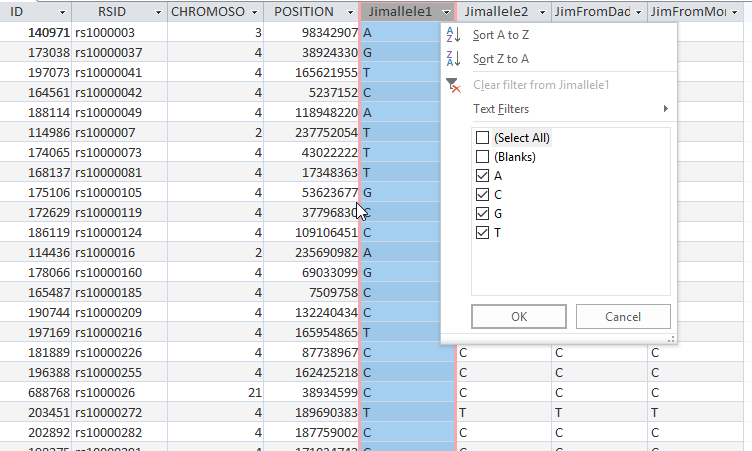

This gets rid of about 17,000 blanks.
This tells me that Mom has 496,136 homozygous alleles, but 381,721 of those Jim already has. That means we need to add 114,415 maternal alleles to Jim’s list. That would get his AllelesFromMom up to 606,174.
Next, I want to get a list of all of Mom’s homozygous alleles that Jim doesn’t have, so we can add them to Jim’s list. There is a little trick to getting this in
Access. First I create an unequal join:

On the query above on the left are all of Mom’s homozygous alleles On the right are Jim’s homozgous alleles that match Mom’s homozygous alleles. The #2 radio box is checked. That means I want everything on Mom’s side and everything where the RSID’s are equal. However, in the criteria, I’ll put an ‘is null’ on JIm’s side:


This adds 97,451 of Mom’s homozygous alleles to JIm. This is less than the 114,415 that I was looking for. One guess is that these are positions that Mom had tested that Jim did not. Somewhere I lost 7,000 of Mom’s homozygous alleles. Or this may have to do with the blanks in some of the tables. I was able to get rid of the blanks in Jim’s table and the new number came out right:

Adding 114,000 Maternal Alleles to Jim
Now that I’ve found 114,000 maternal alleles for JIm, I’d like to add them to his table. There are probably a few ways to do this in Access. One way is called Append Table. I’ll try that as I will need that later on in the process. If only I remembered how to do that. I could put Jim’s table into Excel and just add Mom’s table. However, I’m not sure Excel will appreciate the large files.
The directions that I found for Append Query said to use the data you want to copy first. That was in this Query:

What I want to add is from a Query called Mom Homo Jim Missing. These were Mom’s extra alleles. I chose to append these to a table called Jim Homozygous. But on second thought, I want it going to a new table, so I’ll copy Jim Homozygous and call it Jim Plus Mom Homozygous. First I want to review the results using the view button. I guess it looks right. It only shows the records to be added. Then I push Run and I get a warning saying that this cannot be undone.
Here is what the Appended Table looks like:

This is the point at which the appending took place. What I wasn’t expecting was that Access added the ID. This is the ID that Access originally assigned to the raw data. So now I have Jim’s ID’s and Mom’s ID’s in the same Table.
Phased Allele Update Alert

These two operations based on homozygosity alone put Jim’s phased alleles at over one million. Bing, bing, bing. Jim is already almost 80% phased. Maternally, he is close to 88% phased.
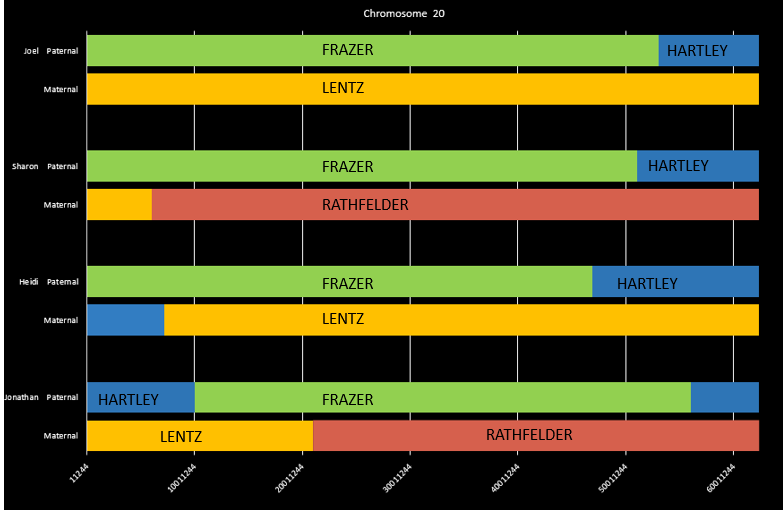
Other Phasing – Visual
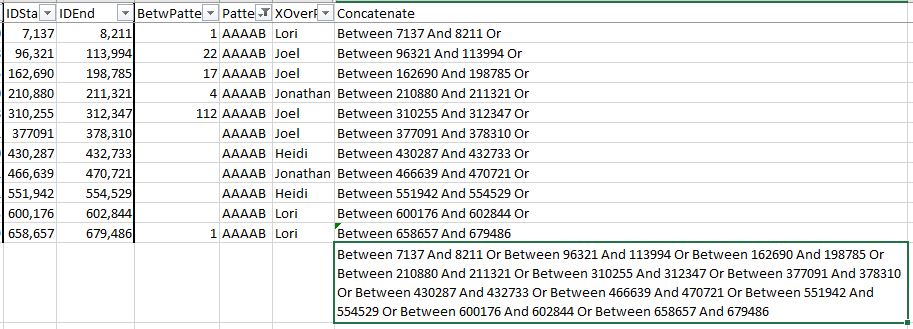
I’m not the most experienced raw data phaser in the world, but I have worked on three, four five, and now six sibling raw data phasing. I have also done a lot of work with three, four, five and six sibling Visual Phasing. Here is Chromosome 1 using the Steven Fox Spreadsheet:

I can use the raw data phasing to confirm the Visual Phasing. I can also use the Visual Phasing to know where to look for crossovers. For example, I already see a problem with the map above in the bottom right corner. I will need to change the crossover designations there.
The other reason stated at the top of the Blog is that I should be able to create a file to upload to Gedmatch for each of these four grandparents. That could make searching for DNA matches easier.
Summary and Conclusions
- I started phasing the sixth of six siblings based on homozygosity.
- Using homozygosity alone, I got my brother Jim up to 80% phased.
- Raw data phasing is considered an advanced topic, but the basics are quite simple. If you have two alleles that are the same, one must be from your father and one from your mother. If you are a parent and you have two alleles that are the same, you had to have passed down that same allele to your child.
- I also used MS Access which is best suited for large databases.
- My goal is to get four grandparent files to upload to Gedmatch (or Genesis). In the past, I have run out of steam on these projects.
- I will be able to use my past work on visual phasing as a roadmap to finding crossovers and assigning grandparents.
- I should be able to use my past raw data phasing experience to streamline the process.
- With six siblings, I am expecting good results. However, as in the Visual Phasing process, the more siblings you have, you will have more combinations of sibling comparisons you have to look at.
- Next up, I expect to look at heterozygosity.