
In my last Blog, I said that I would work on the Maternal Patterns and then fill in blanks. However, my Maternal Pattern Table is not very filled. After some thought and re-reading the Whit Athey Paper on Phasing, on which I base this work, I decided to:
- Fill in the Paternal Blanks
- Use the Paternal Data to fill in the Maternal alleles
- Fill out the Maternal Pattern Table
- Fill in the Maternal blanks based on the Maternal Pattern Table
Filling In Paternal Blanks
I might as well start filling in the AAAAA Patterns. On my Dad Pattern Excel Spreadsheet, I can filter for that pattern:

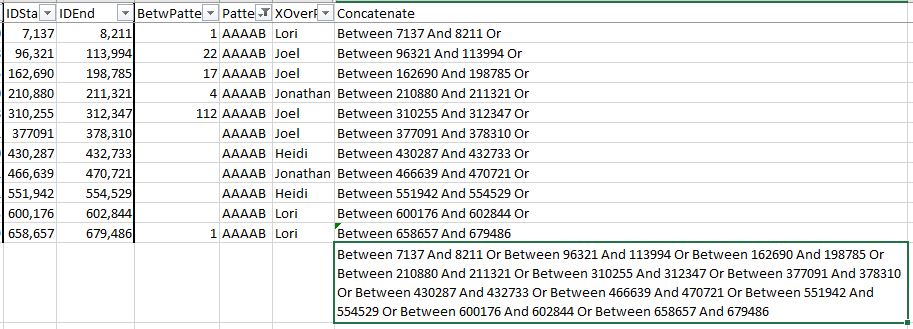
However, I now need a formula for Excel including all the ID positions above. This was the point of my starting this project over – to get those IDs. The formula will be in the form of “Between A And B OR Between C And D OR…” So first I need a formula in Excel to create the formula in Access. That formula is called Concatenate. According to a Google search, concatenate means to “link (things) together in a chain or series”. The symbol in Excel for concatenate is simply the ampersand (&).
Here is my formula and the outcome:

However, I have another idea. I can concatenate the concatenation. First, I add an extra space on the end of my “Or”. Then I drag down the formula to fill in the other chromosomes. Then I take off the last “Or”.


That gives me this helpful string of AAAAA Positions:

This will save me a lot of cutting and pasting in Access.
Back to Access
First I copied my old Table to a new one called tblFillInOne. I will create an Update Query for that Table.

I am only updating Dad alleles from other Dad alleles, so I import those 5 alleles plus the location ID. Then I use the expression builder, to paste in the location of the AAAAA Patterns in all 22 chromosomes. So now I have the Pattern and the location, but I need some more criteria. I would like the criteria to say if there is any allele in any of the five columns and any blanks in those columns, then replace the blank space with one of the existing alleles.
Here is a simple Update Query:

This says, that if my allele is null and Sharon’s isn’t, then replace mine with Sharon’s. The problem is that this would take four separate Update Queries. With 5 siblings, that would be 20 queries.
Another risky Update Query would use this form:

Here I am saying if any allele is not null (other than mine) replace that in my slot where I have a blank. The thing I don’t know if the Update To: field can have a variable criteria. I’ll try it. When I run this as a Select Query, it puts a bit of a strain on my computer. Eventually, it gives me 18,385 rows. When I run the View function on the Update Query, I get the same number of rows, so I’ll hit the Run button and hope for the best.
If I run this Select Query again, I should get no results if everything updated. I did get no results, so I assume that it worked. I want to save this Update Query and use it for the other four siblings.
Filling in Sharon’s missing alleles from the AAAAA Paternal pattern
I used the same logic for Sharon:

Now she has all the Is Null values and I don’t. I moved the Update To: criteria over to Sharon. I took out Sharon’s allele and added mine in her place. Again, this gives my old computer a workout. I get 18,315 rows again which seems suspicious. I see the problem. I appears that Access updated my results with a (-1) rather than with an allele.

That means that I just have to do 20 Queries. However, they should go quickly.
Back to the Simple AAAAA Query
Due to all the Update Queries, I’ll make a Spreadsheet to keep track of each Update Query I do:
![]()
It turns out that it is easier to run this Update Query sorted by ‘From’:
![]()
That way, I can just move Sharon’s allele from Dad and the Is Null along the Update Query:

With these fast 20 Update Queries, I updated over 100,000 alleles:

AAAAB Fill-in
This could be a little easier. For this one, we don’t want to touch the last ‘B’. The last B represents Lori, so we will only be filling in to and with the other four siblings.

And then we need the fill-in locations.

AAABA and AAABB Fill-in
AAABA is about the same as AAAAB except the B in the AAABA corresponds to Jonathan. He is all alone as a B so he gives no alleles and takes no alleles. The other siblings share their AAAA’s in this Pattern.
In an AAABB Pattern, the three A’s will share with each other and the two B’s will share with each other. This happens to break down along V1 and V2 lines, so I expect there will not be as much sharing as between AncestryDNA versions. The sharing of A’s and B’s looks like this in my Fill-in Tracker:

I have darkened out the areas where an A cannot share their A with a B and a B cannot share their B with an A. As I predicted, the AAABB filled-in alleles were less:

All the other patterns filled in
All the other patterns will be of the same type. There is one AAAAA which is all the same. The other combinations are four of one type and one of the other or three of one type and two of the other.

There are 20 fill-in’s for AAAAA. As a quality check, there are 12 fill-in’s for a 4-1 Pattern and there are eight fill-in’s for a 3-2 Pattern. I would recommend using a fill-in tracker to make sure all the combinations are being covered. The specific numbers of alleles being filled in for each combination of each Pattern are not all that important, but they are interesting.
Fixing an abbab mistake
When I was filling in the ABBAB Pattern, I noticed a mistake I made. I filled in 3754 rows of Joel alleles into Heidi blank spots. In an ABBAB Pattern, I am only supposed to be filling in my alleles into Jon’s blanks. Here is the mistake:

That means in those positions, I’ll have an ABAAB Pattern where I should have an ABBAB Pattern. Oh no. So how do I fix that? I need a fix query. Under Pos ID, I’ll put in all the locations that are supposed to be ABBAB. Then I’ll make sure the first position isn’t the same as the second:

That results in only 103 rows.

If I update those 103 rows to Null, that should be a start:

Next I set the first position to be different than the last in this ABBAB Pattern:

That fixes another 212 rows. That may be all the rows to fix. I looked for more JoelfromDad = Heidi from dad where JoelfromDad <> LorifromDad and where JonfromDad <> LorifromDad, but didn’t see anything. The other updates must have been in areas with AAAAA by chance areas. In the meantime, I copied the first two columns on the left to the right, so I don’t lose my place when I am scanning across the spreadsheet.

Dad Pattern Fill-in First Round

The dark blue areas are the ones where there should not be any filling in based on the Pattern.
Summary
- The Fill-in Step is a major part of phasing. In this step I filled in over 1 million paternal alleles in my DNA and in my 4 siblings’ DNA.
- I noticed a mistake I made along the way, but figured out a way to fix it.
- I figured out a shortcut to describe the different patterns by way of ID’s. The shortcut involved using a concatenation of a concatenation.
- I haven’t yet filled in the random AAAAA Patterns that are within the other patterns. I imagine that would be important to do at some point. I know that David Pike has a utility to find Runs of Homozygosity. I suppose that would be useful for filling in alleles.