
In my previous Blog, I came up with a way to show my Clusters and how they changed (or didn’t change) between Shared Cluster runs at different DNA match levels. The Shared Cluster Program is from Jonathan Brecher and the encouragement to walk my cluster back was from Jim Bartlett. As a result of my previous Blog, I thought that it might be easier to walk my clusters forward instead of back. Usually in genealogy work proceeds from the recent to the more distant path and from the known to the unknown. However, after looking at the clusters, it seems that in some ways the older clusters are more specific.
Using MS Access to Walk My Clusters Forward
I used to have some knowledge of MS Access. I wonder if I can resurrect that. I want to take my 6 cM run from my previous Blog and compare it to my 25 cM run. I hope to map 50 clusters down to 27. So I am reducing the clusters by about two to one.
I’ll start with a new Access database:

This database had a blank table in it for me to add data to. I didn’t want that, so I got rid of it. I’ll go to External Data and import my 6 cM Shared Cluster Run. I feel like I should close out my open copy first.

I chose New Data Source and found my file. When I sorted by Date modified, my file rose to the top.
This leads me to an import wizard:

I probably won’t import all the information. I clicked the box saying I wanted my first row to be the Column Headings.
Actually, I see a better way to do this. I went back to my original file and copied columns A-L:

I put these into a new file, saved it and imported that into Access. I don’t need any of the 2500 or so columns after L. This brought me to the import wizard again. I pressed next:

Access want to add a primary key or to choose a primary key. The test ID is an ID, so I’ll use that. Otherwise, Access will assign the numbers of 1 to about 2500 to identify my new database.
Next, I give my table a name:

This now shows up in my Access Database:

Next, I do the same for my 25 cM run as I want to compare the 6 cM run to the 25 cM run.
Querying Access
The next step is to use these two tables to see how the 6 cM Clusters look like at the 25 cM level.
I’ll choose Create > Query Design:


I’ll choose these two tables. That will put them onto the blue area, then I’ll connect them by the key ID:

I wasn’t sure what to choose from the tables above to put into the query below. I put in the name. This has to be the same in each table because the Test ID in each table corresponds to the same name. Most important is to map the 6 cM Cluster Number to the 25 cM Cluster Number. I have those columns plus the 6 cM Correlated Cluster Number, the 6 cM Common Ancestors and 6 cM notes. The notes should be the same for each table. I didn’t add the 25 cM Correlated Cluster Numbers. I can add those later if I find I need them.
Next, I choose view to get the results of the query:
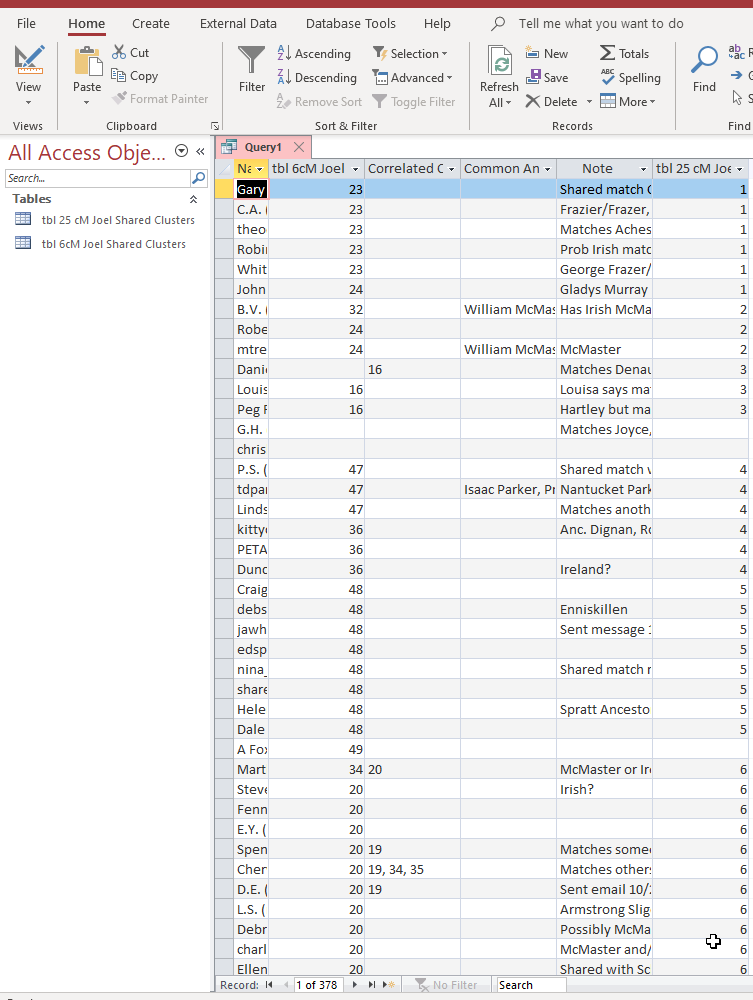
I get 378 results. This makes sense as there were 378 results in the 25 cM Shared Cluster Table. For some reason, Access ordered the results by the number of the 25 cM Cluster Number. This isn’t so bad.
Easy Results
Next, I’ll move the 25 cM Column in closer so I can compare the two sets of cluster numbers:

Let’s look at the 25 cM Clusters 1-3. Walking back, Cluster 1 went to mostly to 23, but one went to 24. Cluster 2 went to 24 twice and 32 once. Cluster 3
only went to Cluster 16. My guess is that the mixup between Clusters 1 and 2 have to do with the fact that these Protestant Irish families intermarried.
A Flaw in My Logic?
I’m just thinking that I need to do this exercise at least one step further back as I haven’t yet finished filling in my 25 cM Clusters. I’ll see what I can do with just the information I have sorted out from Access so far.

Without any sorting of my query, it appears that Cluster 40 comes out of nowhere. However, when I sort by the 6 cM clusters:

Here is a situation where Cluster 40 must be a compound cluster. Here is what I see:

The smaller square at the top left may be Lentz. The single dark red square in the bottom right is Nigel. I mentioned him in my last Blog. He represents an old Nicholson DNA match.

Nigel would not match the Lentz side which appears to be the top left side of the Cluster. There appears to be other sub-clusters within the Nicholson Cluster which may represent Ellis or Clayton highlighted above.
Because, I’m in the area of my 25 cM Clusters that I didn’t finish last time, I want to do a new Access Query
Comparing My 30 cM Clusters to My 25 cM Clusters in Access
Here is what my new query looks like:

I’ve connected the two tables by the Test ID. Then I compared the 25 cM Cluster Number to the 30 cM Cluster Number. Plus I added some more information that I though to be helpful. Actually I had the Name column twice which was not needed.

This is my Nicholson section. This shows that the 30 cM Cluster 14 mapped to two clusters at 25 cM. I’m glad I did this, because Cluster 25 splits between Lentz and Rathfelder due to my mother being in that Cluster:

This brings up another issue. At 20 cM, my Rathfelder 2nd cousin match aligned with my maternal 1st cousin and her two daughters. This caused them to form a single Cluster that mapped from a previous two Clusters (25b and 11). It’s not a big deal, but I had to just enter 38 twice to account for it. To be consistent, I’ll call them 38a and 38b:

Here the green square represents 38a with my first and second Rathfelder cousins:
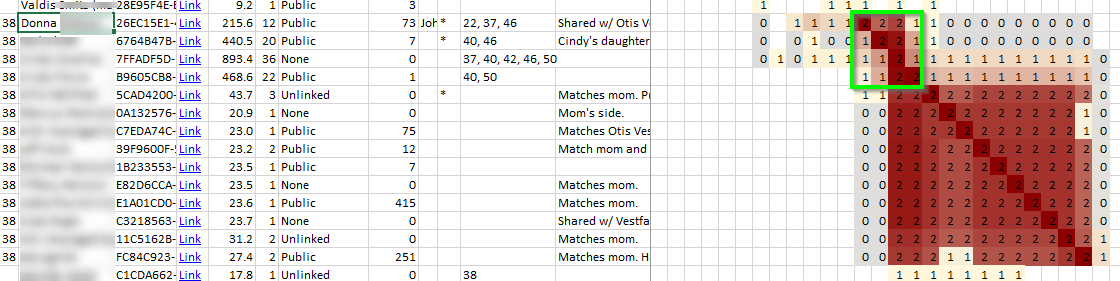
The matches to the lower right of the green box would be my more distant relatives with ancestry in Hirschenhof, Latvia.
Finding Cluster 22 at 25 cM
When I compare my 25 cM Cluster to my 30 cM clusters:

Cluster 22 at 25 cM has no precedent at the 30 cM level. That has to do with the match level of Cluster 22. Here is a comparison with it’s corresponding 6 cM Cluster:

All these matches to me were under 30 cM. So basically, Access makes it so you don’t have to keep switching back and forth between the different results.
Solving the Puzzle: Filling in the 20 cM Clusters
The 20 cM and the 6 cM Clusters are the same. The Shared Cluster can look at how the matches between 6 and 20 cM are associated with Clusters but Ancestry doesn’t make shared clusters at less than 20 cM.
I have some filled in already, but need to get up to 50 clusters:

The first Cluster 19 mapping is an issue:

25 cM Cluster 19 maps to Clusters 6, 7, and 15 at the lower cutoff. Further, I can see at least three clusters within the new Cluster 7:

The two green squares represent points of interest for me. They appear to represent my Hartley English genealogy.
Backing Up a Step: 30 to 35 cM Clusters Compared with Access
Another way to use access is by using an unequal join:

The unequal join is represented by the left to right arrow above. That says, show me all the cases where there is a value in the 30 cM cluster table that is equal to a value in the 35 cM cluster table. And it adds in all the remaining 30 cM clusters that aren’t included in the 35 Cluster Table. I think that that is what I want. I could have had the arrow go the other way, but would have gotten different results.
Just for fun, I’ll do it both ways. This is the way from above:

This shows that Cluster 2 at the 30 cM level had no corresponding cluster(s) at that 35 cM level. Cluster 4 only had one corresponding Cluster. And in that corresponding cluster, Cluster 4 had a correlated Cluster 7.
Here are the results with the arrow going the other way. Think of the previous results as walking the clusters back and this new one as walking the clusters forward:

Here Cluster 2 doesn’t even show up at the 30 cM level. They both give about the same information, but the walking forward comparison should provide more detailed information.
Cluster 7 at 35 cM
I’d like to take another look at this as I had ignored this Cluster previously. Based on the above query, it turns out Cluster 7 is quite important. This is Cluster 7 at 35 cM:

The first two people I have as coming from Nantucket (my paternal grandfather’s side). The second two I had guessed as being from Ireland (my paternal grandmother’s side). I don’t think that they belong in the same Cluster, so I’ll tree this as two clusters.
Putting It All Together with Access
Here is a more complicated Access Query:

Above, I’m comparing the 6 cM table to the 25, 30 and 35 tables. I have the link between the 6 cM Table and the 25 cM Table a right handed link, so I’ll see all the 6 cM (or 20 cM) Clusters. I then put the 35 cM Clusters first so they will be in the order of my Summary Chart:
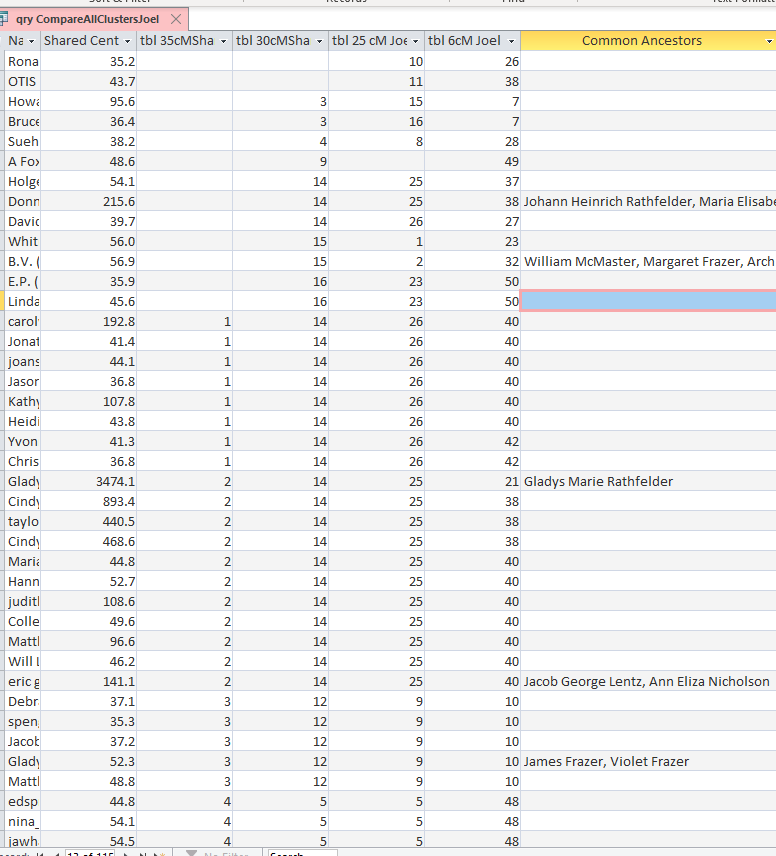
At 35 cM I have 10 Clusters. Cluster 1 maps to Cluster 14 at 30 cM. 14 Maps to Cluster 26 at 25 cM. Cluster 26 maps to Clusters 40 and 42 at 6 cM. However, note that other clusters are mapping to Cluster 40. That is because we have Lentz and Nicholson in Cluster 40 as well as those who only descend from Nicholson, if I understand it correctly.
Cluster 2 at 35 cM includes my mother. Her clusters go from 2 to 14 to 25 to 21. The correlation is one to one until we get down to the 20 cM level. At that point the cluster splits into three where Cluster 40 is a child of Cluster 1. That makes me think that Cluster 40 will be a compound Cluster.
I see at least three clusters for Cluster 40 at the 20 cM cutoff:

Another Query
This one is more like the manual comparison that I did previously:

This query says take everything in the 6 cM Table plus those things that match inthe 25 cM. Then do that for each Table. That query appears to give me everything as it includes 2,452 rows:

Here is a stripped down version of this query:

Here I only include the Cluster Number columns:

This gives me 135 rows. This also points out that Cluster 6 and 10 at the 35 cM level both map to Cluster 7 at the 30 cM level. This makes sense when you look at Cluster 7:

This is a distinction that I had missed in my original mapping chart:

This corrected chart better reflects what Access is showing me:

Access then shows this:

The part of Cluster 7 that was from 10 goes to 18 and then to Cluster 5. This was not reflected in my previous summary chart:

Here is the correction:

I’ll also add in my Cluster 7 at the 35 cM level. I didn’t add it in previously as it had 2 people with Nantucket shared ancestors and 2 people with suspected Irish shared ancestors.

Mapping Cluster 4 at 30 cM
Here I have another situation like my Cluster 7 above:

This is another 4 person Cluster. And, like Cluster 7, the first two people seem to match on my Hartley side and the second two seem to match on my Frazer or Irish side. This is reflected in my Access query:

The split goes to Cluster 8 (Irish) and 14 (Hartley ancestors).
Mapping Cluster 14 at 30 cM
Here is the work I did previously in my Cluster Summary Chart:

I had split Cluster 14 in three. These are my major maternal lines. Because my mother was in this Cluster, she was related to both these sides. Lentz and Nicholson are well-tested, so I have some good separation there. This confusion is reflected in my Access query:

The Common Ancestor Column above shows three different sets of Common Ancestors. They represent the needed splits for Cluster 14. This is where the Access results come in handy. In Access, I have a 14 Cluster going to Cluster 26 which goes to 27. I had missed that in my previous analysis and only had 27 going to Cluster 40.
My Irish Cluster 15 at 30 cM
Here is what I had:

The Access query shows some additional subtleties:

This shows Cluster 2 at 25 cM going to Cluster 24 at 20 cM. However, that doesn’t mean my other Cluster 2 to 32 is wrong:

Two other people in Cluster 2 probably would have mapped back to Cluster 15 but the DNA match was not high enough to be in Cluster 15. Also note that Cluster 24 and 32 both have Common Ancestors:

The question is, if these three have the same common ancestors, then why are they in different clusters? The answer appears to be that one Cluster (24 or 32) would represent McMaster and the other Frazer due to the two common ancestors.
As a result, I split out these two clusters like this:

McMaster 1829 is Fanny in Cluster 2 above. I now have Clusters 24 and 32 as her parents. Consider it a theory.
The Good Enough Product

I have slimmed down my chart to show between 40 cM and 20 cM. I started with 5 clusters in the 40 cM Column which is enough to describe my four grandparents. In the 20 cM column, I didn’t feel a need to describe each of the 50 clusters. However, I was interested in describing each cluster in the 25 cM column and it’s corresponding cluster at 30 cM and 20 cM. The 25 cM clusters were at a good vantage point where I could check the clusters on either side using Access. The place where I may be more interested in detailed 20 cM clusters would be for my English Hartley side.
Summary and Conclusions
- Jonathan Brecher’s Shared Cluster Program is good for sorting out your clusters
- The use of MS Access makes it easier to see the nuances of how the clusters merge or separate between the different lower match thresholds
- There is a question of my mind concerning the level of accuracy needed in this analysis. It’s good not to be so detailed-oriented that you miss the big picture. The big picture for me is whether the cluster is in the right grandparent group for me.
- This was my first shot at using Shared Clusters to sort out my Ancestry Clusters. I’d like to try using the Shared Cluster program on other DNA kits that I administer. Perhaps my mother’s results would be the next logical step.
Good stuff. Diligent tracing of mrcas. Just a note that some usernames slipped into this blog unblurred.