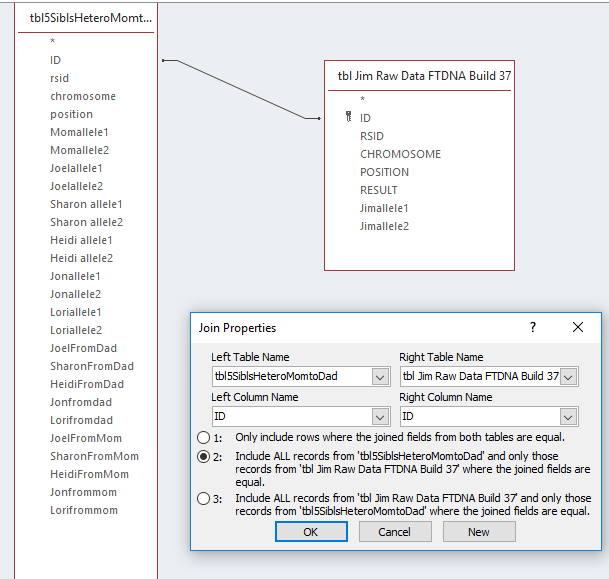
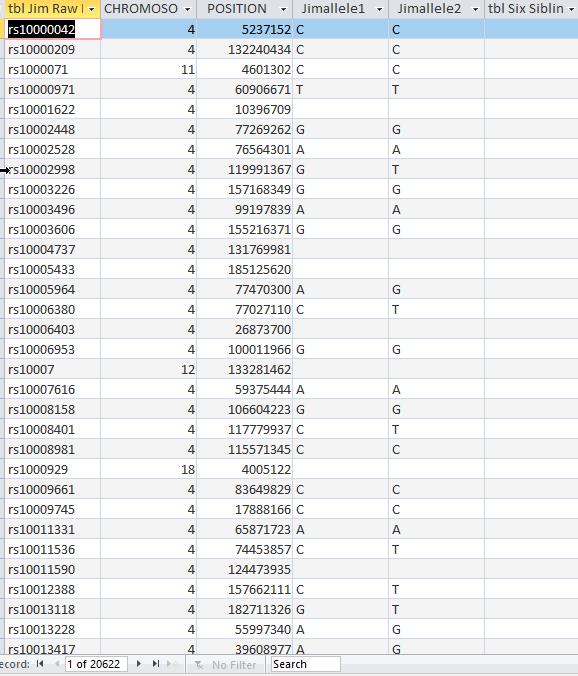
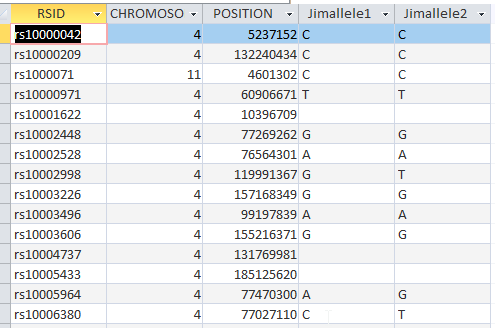
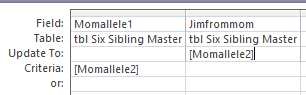
I noticed that the Genetic Affairs Facebook site had a recent post. They said that as a Christmas present Ancestry AutoClustering was back in operation with some new controls to limit problems with the autoclustering. Ancestry AutoClustering has been popular. That is because AncestryDNA has the largest database of DNA-tested people but they are lacking in analytical tools.
My AncestryDNA AutoCluster
When AutoCluster first came out, I tried it at the low default settings. I wrote a Blog about those results here. Here are my annotated results:


I was impressed with the results and even though my clusters were small based on the default parameters, I liked the simplicity of the five clusters.
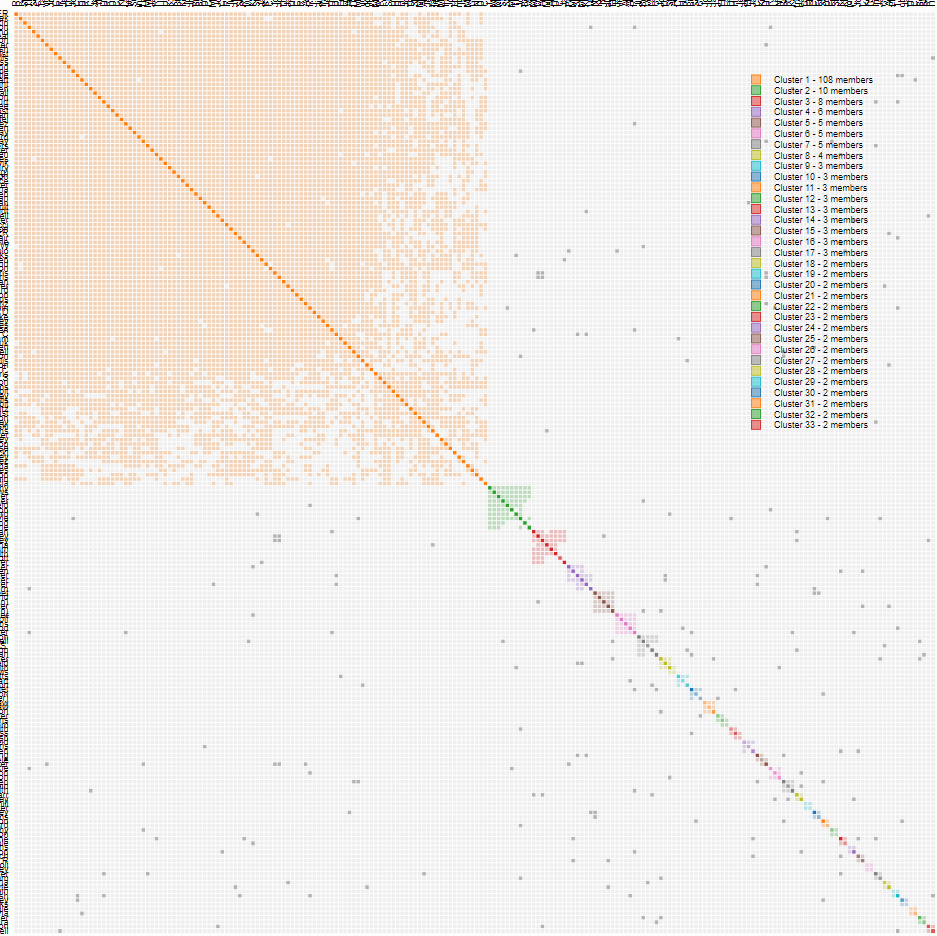
Here is my latest try at autoclustering. Now I used defaults that were 600 cM on the high end and 9 cM on the low end:

Now I have gone from five clusters to 76.
My Genealogy and Deciphering Some of the 76 Clusters

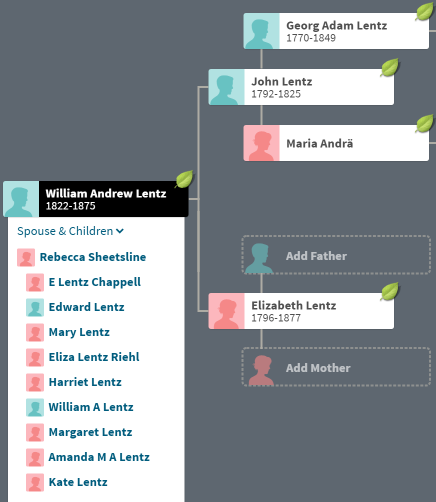
This tree goes to 16 branches. I suspect that 76 branches could go back at least two or three more generations than above. I have a lot of Hartley relatives as my great-grandparents had 13 children. My great-grandmother Snell had colonial Massachusetts ancestry. That means that I have a lot of 2nd cousins.
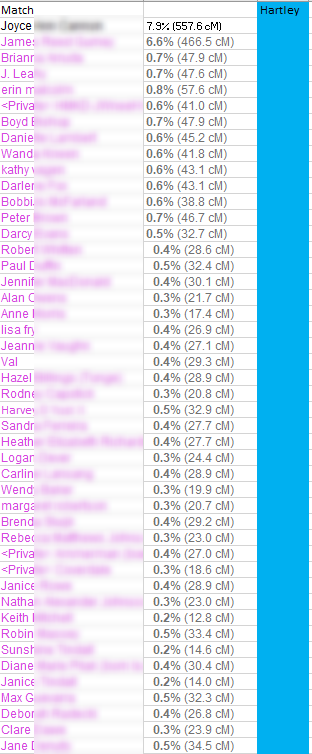
My Hartley 2nd Cousins
My Hartley 2nd cousins are not found in Cluster 1, but in Cluster 4:

These are my top 13 clusters. In my previous analysis, the present Cluster 4 was #1. By expanding the matches out to more distant matches, the new Clusters 1-3 beat out my former #1 Hartley 2nd cousin Cluster. Along with my 2nd cousins in Cluster 4 above are a few more distant cousins.
Massachusetts Colonial Ancestors – Cluster 1
Cluster 1 appears to include many of my more distant Colonial Massachusetts ancestors going back past my Hartley side. My closest match in Cluster 4 is my father’s cousin Joyce. My closest match on Cluster 1 is Jonathan – a relative of Joyce. Previously, Jonathan was in my old Cluster 1 also. Now he is a ringleader for my Colonial matches.

Other than Jonathan, I cannot pinpoint exact common ancestors for matches in Cluster 1 at this point.
My Largest Matching Clusters
Next, I am going to change my strategy. I will now sort by match on my Cluster List:

I clicked on the cM button until the arrow was pointing down. This gives me the clusters with the largest matches. Hence, the matches that I am likely to know about. The highest matching cluster is #4. #12 is the 2nd highest match. That is because it includes my 1st cousin’s daughter (on my mother’s side). That means that Cluster #12 could be either on my mother’s mother’s side or my mother’s father’s side.

The next Cluster by size is #1 with Jonathan.
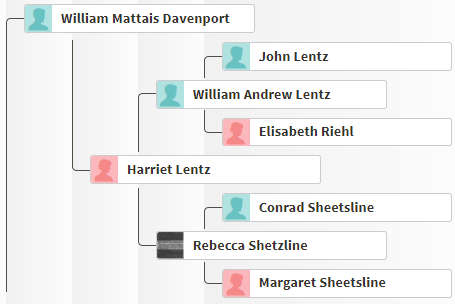
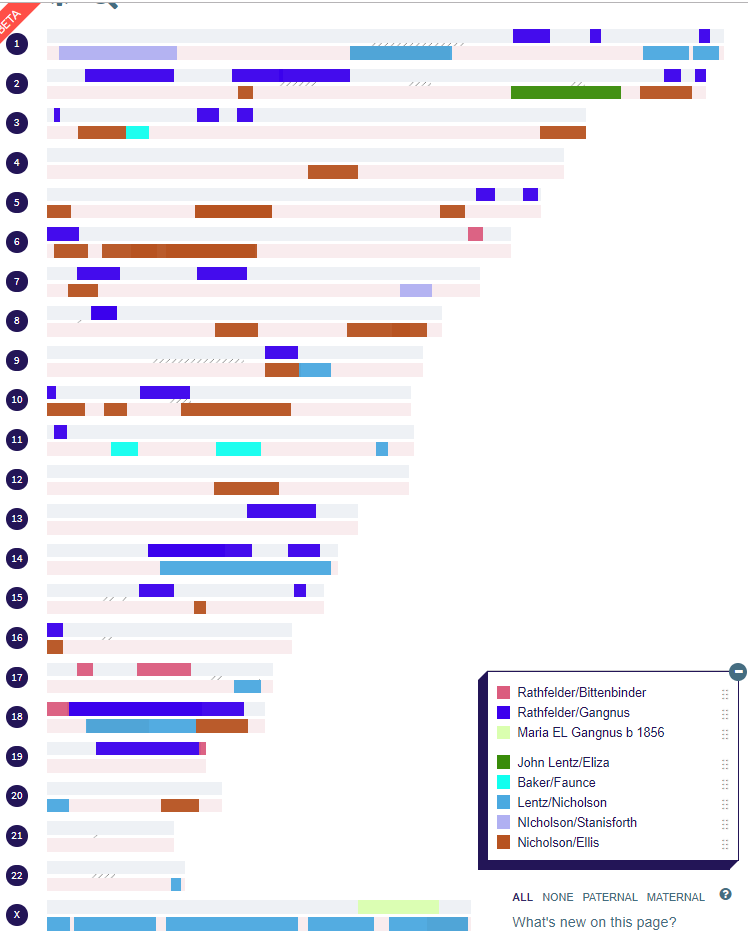
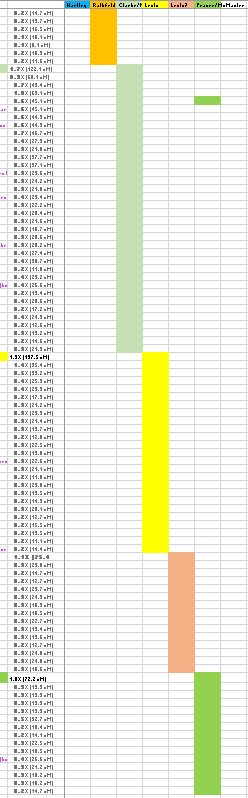
Cluster 16 – Nicholson
The next cluster by size goes off my present image, so I will need to ratchet down the image. Cluster 16 has only nine people in it, but I have been in touch with many of them. The known people in this group descend from William Nicholson and Martha Ellis:

Cluster 27 – Clarke
Cluster 27 is important to me. Clarke is my largest brick wall. I will have to go down yet another level for Cluster 27.

I’m starting to use the Key for these higher number clusters.
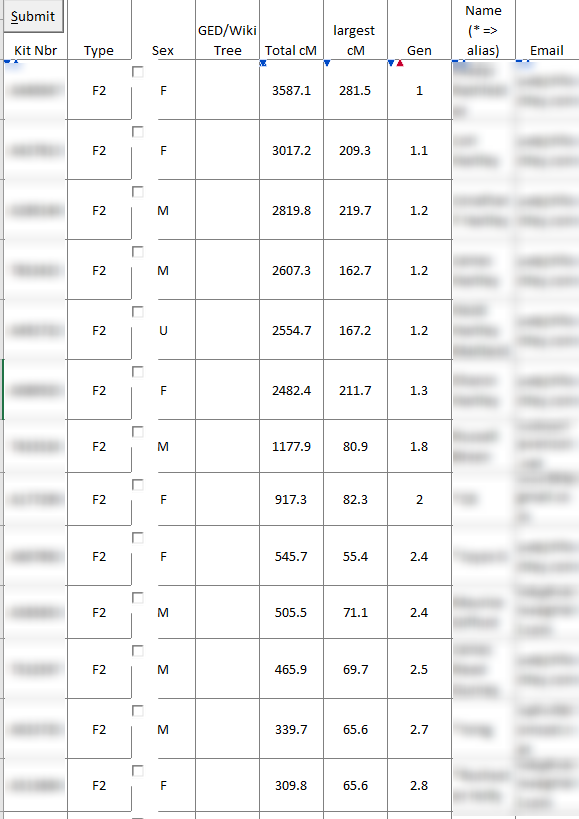
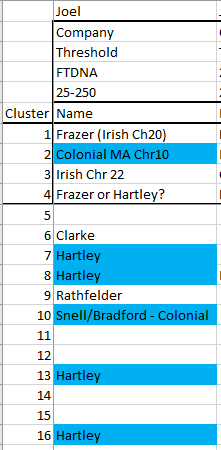
My Top 23 Clusters by DNA Match Level
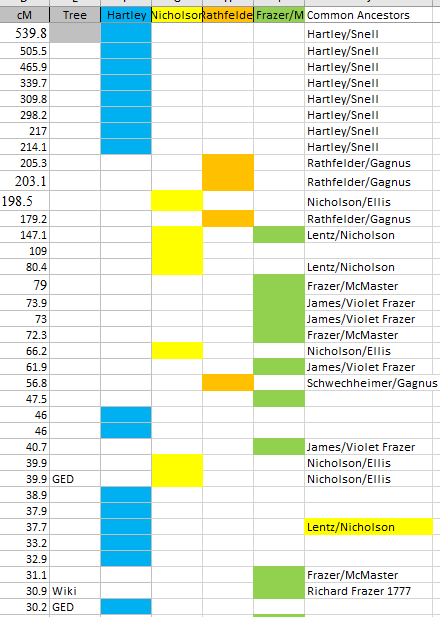
Here are my top clusters by match level in a spreadsheet:

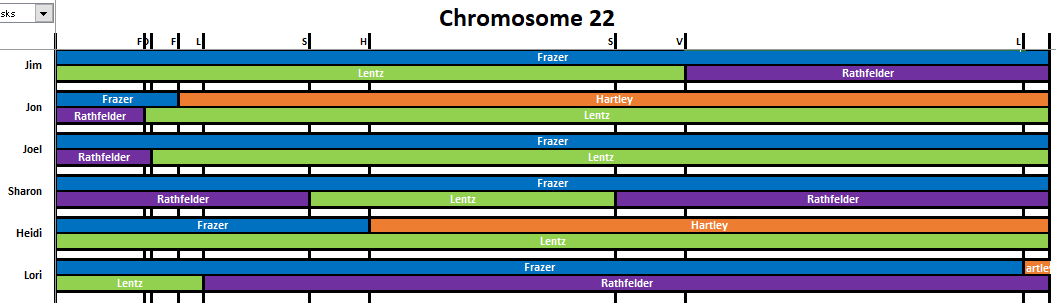
This shows that the highest matches are on the paternal sides and on that paternal side, most of the matches are on my Frazer grandparent side.
I can also sort by cluster:

This shows that I am missing Cluster 3 even after looking at my top 23 clusters.
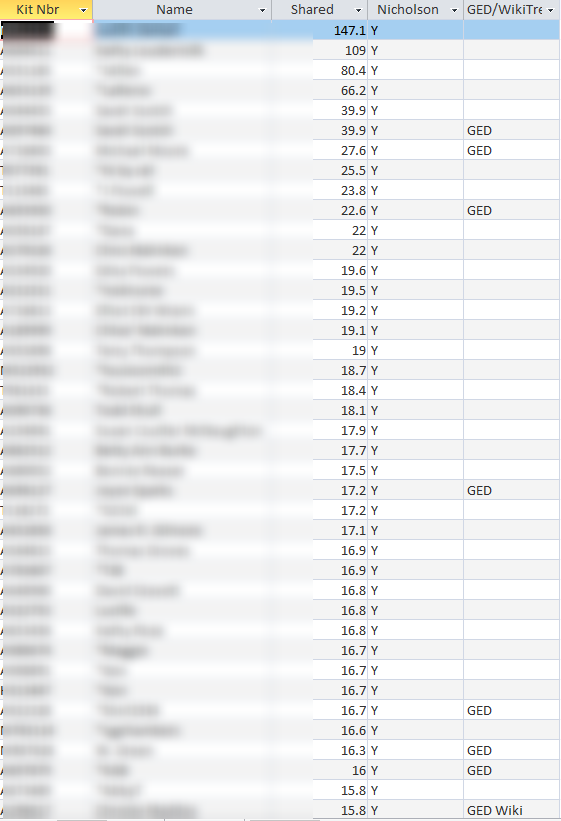
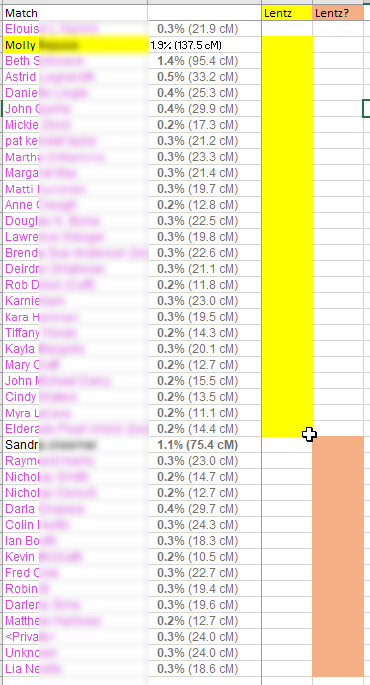
Cluster 3 – Mom’s Side
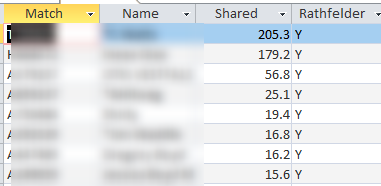
That makes me curious about Cluster 3. From the match list, I see that the top match is at 27.1 cM. This person has a large private tree, but hasn’t logged in to Ancestry for over a year. This group of matches is a bit of a mystery. I know that this cluster is maternal and probably the Lentz rather than the Rathfelder side as the Rathfelder matches are on the rare side.
Old Cluster and New Cluster
My original AutoCluster was done at conservative default levels and resulted in five clusters.

The old Cluster 1 is found in new Clusters 1 and 4. 2 is now 6 and 27. 3 is now 11. 4 is now 17 and 71. 5 is 19.
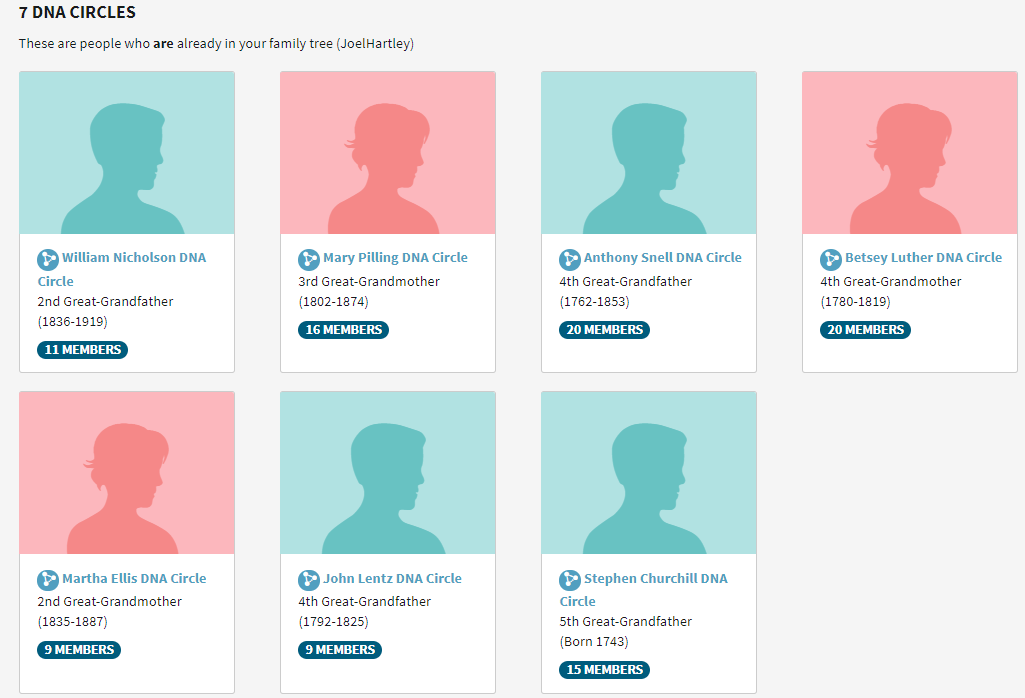
AncestryDNA Circles
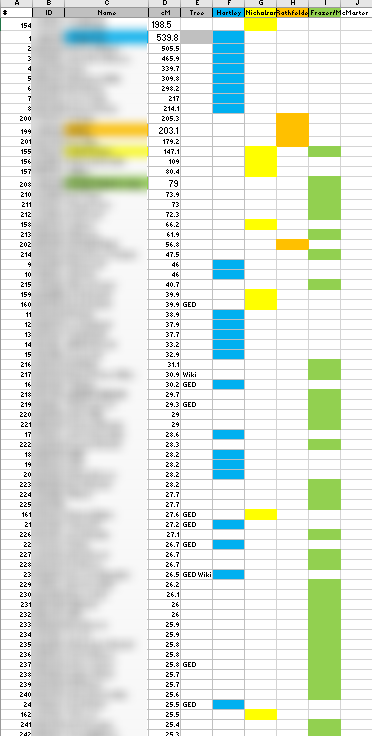
It occurs to me that it would be helpful to compare clusters to the AncestryDNA circles. Here are my circles:

Nicholson, Ellis and Lentz are maternal and the rest are paternal. Nicholson and Ellis are both in Cluster 16. This points out an error I made on my spreadsheet:

I previously had my Nicholson Cluster as 11 and it should have been 16. My mother’s Lentz circle was emerging and the few matches were either not matching me or too low to be in a cluster.
The Mary Pilling Circle is interesting as this goes back to England. However, those in the circle who are not my 2nd cousins are a match to the circle and not to me.
Descendants of Anthony Snell Circle
I have a similar problem here. There are two people who are not second cousins to me that match me by DNA, but they match at levels below 20 cM. If I check the shared matches of one of these matches, I see that he matches Fred from Cluster 30. That is perhaps a hint as where I may find a common ancestor with Fred. Shared matches with another person in this circle also lead me to a three people who are in Cluster 30.
I believe that the Betsey Luther circle is somewhat redundant. She was the wife of Anthony Snell. Finally, the Churchill Circle. I match second cousins and others in the circle match those second cousins or closer matches. If I run clusters for others in my family, these relationships may be helpful.

This shows that three of my circles are associated with my second cousins in Cluster 4. Shared matches from the Snell circle brought me down to Cluster 30. The two circles for my mother’s side were the husband and wife Nicholson and Ellis. My mother had another Lentz circle but the matches were too low for me. When I look at my mother’s matches, I may find closer matches.
NADs and AutoCluster
NADs are New Ancestor Discoveries. Here are my NADs:

I have no idea who these people are.
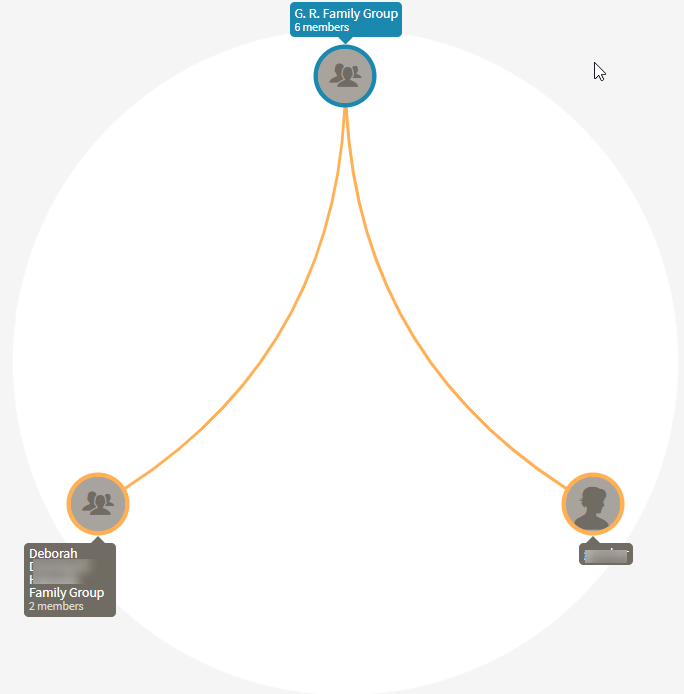
The Long NAD
Here are some of the people in the Long NAD:

The orange indicates a match to me. So these are like circles or clusters also. The only difference is that these NADs are pointing to ancestors that I don’t know about. I may not know about them because they may not be my ancestors or the ancestors may be further back than the ones Ancestry is pointing to.
Brenda is in Cluster 7. I didn’t try to identify Cluster 7 above as it wasn’t in the top 23 clusters. This means that I can associate Cluster 7 with my Long NAD. I associate the Long name with Ireland. However, this family was from North and South Carolina. Angela is also in the NAD and in Cluster 7. She also matches Ron who is on my biggest brick wall – the Clarke/Spratt Line. Ron is in Cluster 27. Perhaps that indicates a relationship between these two Clusters. I did find one person who is in Cluster 7 who is not in the Long NAD. I’m not sure why. There are 21 in Cluster 7 and 31 in the Long NAD.
The Weems NAD
John Weems was from Tennessee. I see his connection even less than with Seymore Long. My matches to people in this group, when they do match, are below 20 cM. That means that I don’t have an analogous Cluster to this NAD.
Summary and Conclusions
- I’m not done playing with AutoCluster yet. There is still more to explore.
- My original AutoCluster looked at matches between 50 and 250 cM. In this AutoCluster run, I chose limits between 9 cM and 600 cM. The spreadsheet showed matches as low as 9 cM, but the html cluster chart showed matches only down to about 20 cM.
- As I had so many clusters, I found it useful to look at the clusters with the highest DNA matches. These are the clusters that were, for the most part, easy to identify.
- I compared the 76 cluster analysis with the 5 cluster analysis I did.
- AutoCluster does a great job of condensing huge numbers of AncestryDNSA matches and putting those matches into categories.
- AutoCluster gave me a sense of how many matches I had that were maternal or paternal and from which grandparent side those matches came from.
- Next, I would like to look at a lower threshold of 25 cM to narrow down the number of clusters that I get.
- I looked at how AncestryDNA circles related to Clusters.
- Next I looked at my two NADs. One NAD had an analogous Cluster. The second NAD had matches that were two small and didn’t have an analogous cluster.