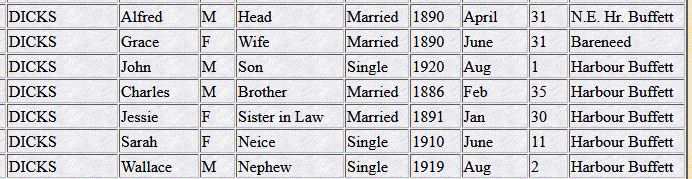
In my last Blog, Part 4, I found that I needed to go back to improve a method from an earlier step to make a later step work much easier. This did two things:
- Gave me a cleaner database
- Set me back a ways
Re-do Principle 1: Homozygous Siblings
I need now to create a new table. This will have the allele from Mom and Dad for each sibling. I copied my previous table to a new one called tblV1andV2HomozygousSibs. I opened my new table in design view and added the 10 new fields that I needed:

The first five of the new fields will be have the Mom Patterns and the last five will have the Dad Patterns. Right now they are just blank. I’ll use an update query to add in homozygous alleles:

This query says when my allele 1 is the same as allele 2 (homozygous), put allele 1 into the slot from my Mom and my Dad. The Dad slot goes off the page, but is there. When I run the update, it fills in over 485,000 lines. To do this by hand would have taken a while. This is the first step to filling in the Mom and Dad Patterns:

I do the same query for each of my four other siblings. Care needs to be made the the right alleles are going in the right place. For example I wouldn’t want to put a Lori allele into a JonfromDad column. Then I check to see if the columns are filling in:

If I recall right, this step fills in (or phases) about 8 million alleles. We don’t see any patterns yet other than AAAAA, but patterns are emerging in other parts of the table.
Step 2 – Homozygous Mom
Here when mom has a GG for example, she would have to give a G to each child at that position, as that is all she has. I’ll use the Update Query again for this. Here is the Criteria:

Here is the Update part:

Step 3 – Heterozygous Siblings
Here is an example:
![]()
I have TC in my two alleles at this position as do my siblings. My mom must have had CC as she gave a C to each of her siblings. That leaves a T that we must have gotten from our dad. It looks like I may need 10 Update Queries for this one. Here is the criteria:

The query says that Joelallele1 is not the same as Joelallele2 (Heterozygous Sibling) and I received my allele1 from mom.

I update the table to say I got my other allele from my Dad. This is a little more complicated Update Query. I then reverse the Joelallele 1 and 2. When I get allele2 from mom, I get allele1 from Dad. Before I run the Update Query, I view it each time to see if there is a reasonable number of rows being updated. If no rows are updated, there is probably an error in my query. This update is in the 40-50,000 row range. Also, if I get values in the view panes, it often means I have put the results in the wrong field. Usually many empty rows in the view output is a good thing.
I forgot to copy and rename my Homozygous Sibs Table, so I just renamed it to tblV1andV2w3Principles.
Finding Patterns
This time, I want to add ID’s to my patterns, so I’ll add two columns to my old Pattern Spreadsheet in Excel:

Rather than do formulae for each pattern again, I’ll just scroll through my table to see if I can finesse the Pattern boundaries and add Position IDs.
Finessing Pattern Boundaries
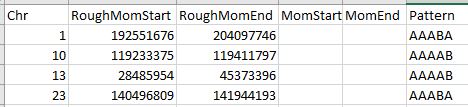
Here is an example at Chromosome 1 in the 77M range. There I had a change from ABBBB to ABABB. In my previous query, I only looked at Dad patterns where all the alleles were filled in. However, in the original pattern, we can infer the pattern even when alleles are missing.

Previously, I had the change at the top row where there is a full pattern. However, in going from ABBBB to ABABB, we only need the first three positions to identify the pattern. And actually, we only need position 2 and 3 to identify ABABB. At ID 25839, there is an AGG??? Pattern. This has to be in the form of ABBBB. Then 4 lines later, is ?AG??. This has to be an ABABB Pattern. Here is how I noted the change in the 77M range on my Excel Dad Pattern Spreadsheet:

The DadStart and DadEnd columns have the refined Position numbers.
Refined Chromosome 1
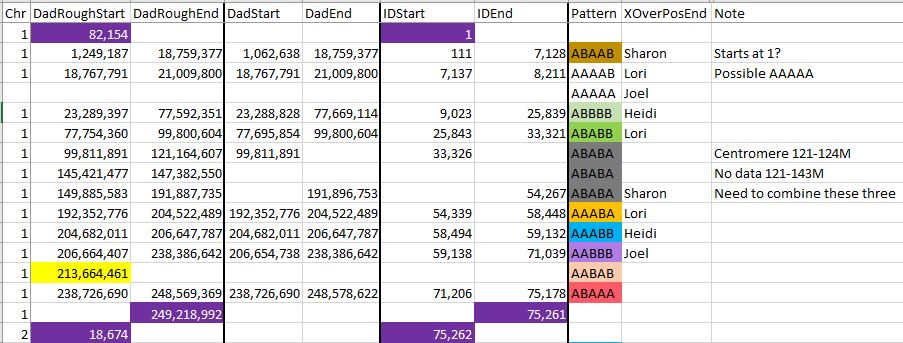
- I had noted previously a possible AAAAA Pattern between AAAAB and ABBBB. It turns out that that is required. This is because to go from AAAAB (same as BBBBA) to ABBBB would require two changes. Only one change is allowed at a time. I will need to fill in the Positions and IDs.
- The three ABABA Pattern areas need to be combined into one. They occur in a Centromere and in an excess IBD area. The Genealogy Junkie has a good Blog on that topic. I downloaded a file she had with the exact areas.
- I added the IDs for the start and stop of the Chromosome as tested as well as the start of the next Chromosome. These are highlighted in dark purple.
- Only 22 chromosomes to go.
Chromosome 2 Refined

Here I added a new column. This is the number of IDs or SNP positions between patterns. Note that there is a negative 4 in one case. This was an odd case where the two patterns at the crossover were inverted. I didn’t know what to do there, so I left it as is. There is a Centromere from 92-95M, so I will combine the two AAAAB Patterns that I have when I create the clean version of this table.
Chromosome 4 refined

Here I had to add a green AAAAA Pattern to make this work. Note that I am getting fewer crossovers.
Chromosome 5
Here is another case where an AAAAA Pattern is needed:

The pattern is needed between AABAA and AAAAB for two reasons. For one, there is a large gap between the end of AABAA and the beginning of AAAAB. Also, to go from AABAA and AAAAB requires two changes and only one is allowed. That requires an intermediary step of AAAAA between these two patterns [AABAA > AAAAA > AAAAB].
Here is Chromosome 5 completed:
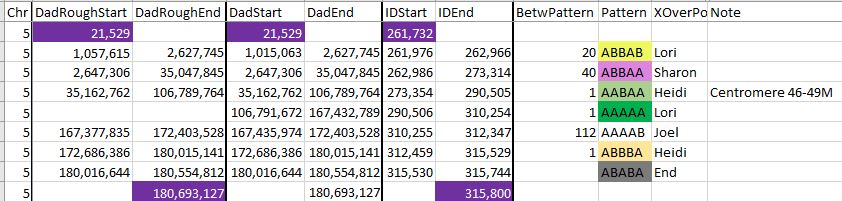
The addition of the AAAAA Pattern results in the addition of two crossovers. Another note is that I could have had the first pattern start at the beginning of the Chromosome and have the last pattern end at the end of the chromosome. That is because there is not much room there for other crossovers.
a chromosome 8 Decision

The issue here is the two AAAAB Patterns in a row. Should they be combined or should I add an AAAAA Pattern between the two AAAAB’s? I’m going with combining. The reason is that if I put an AAAAA between the two, that would give Lori two paternal crossovers in a fairly short span. This does not happen in nature – at least in the middle of a chromosome. This would be like inheriting a 2 cM segment from a grandparent.
Chromosome 9 decision

Lori has two crossovers in a row, which is not ideal. Then there are two ABAAA patterns in a row. I decided to combine these. This is because when I look at the table, there is a centromere in there and a lot of missing SNPs. If I did create an AAAAA pattern, that would result in two close crossover for Sharon.
Here is the cleaned up version with the rogue SNPs taken out:

Missing Pattern Chromosome 10

There is a missing pattern between Lori and Jonathan’s first crossovers. AABAA > ABAAA is two changes, so I need to insert an AAAAA Pattern between the two. This will result in two new crossovers: one for Heidi and one for Sharon.

Chromosome 11 – Halfway?

The good news is that I’m at about 2/3 of the way. I have over 900,000 locations and Chromosome 11 brings us past the 600,000 mark. Note again the need for an AAAAA Pattern between the last two patterns. That will add a Lori crossover and a Jonthathan crossover, so they won’t be left out.
Chromosome 12 patterns

Chromosome 12 looks like it is missing a lot betwee ABBBB and AABAA. However, it is just missing an AAAAA. That is because ABBBB is the same as BAAAA. The progress goes BAAAA > AAAAA > AABAA. As it turns out the crossovers that have to do with transposing relate to me (Joel). The extra crossovers go to me and Heidi.
Here are the numbers filled in for Chromosome 12:

Sketchy Chromosome 13

I note that Chromosome 13 is a bit sketchy, with no identified sibling crossovers. It appears that AAAAA Patterns are needed here also. There is about a 4M space where there is room for an AAAAA Pattern between 24M and 28M. There is also room after the AAAAB Pattern which would give Lori another Paternal crossover. This last crossover is shown in Gedmatch:

These are matches of my father’s first cousin to myself and four other siblings. This shows Lori’s crossover on the bottom match. As all siblings match to the end of the Chromosome, that would be the AAAAA Pattern.
Here is the finished Chromosome 13:

Lori’s crossover as shown in Gedmatch shows on my table at about 90M. Keep in mind that Gedmatch uses Build 36 and my table is in Build 37.
Chromosome 21: Refinement Example
Here is an example of a refinement. In my initial query, I was looking for patterns that were filled. However, in going from AABBA to ABAAB (which defines my crossover), it is the same as going from BBAAB to ABAAB. The only change in pattern is in the first three letters: BBA to ABA. We can see that change here even though the last three letters are missing:


Chromosome 22: Extra AAAAA needed
On Chromosome 22, there is a lot of room at the beginning of the Chromosome to put in an AAAAA Pattern:

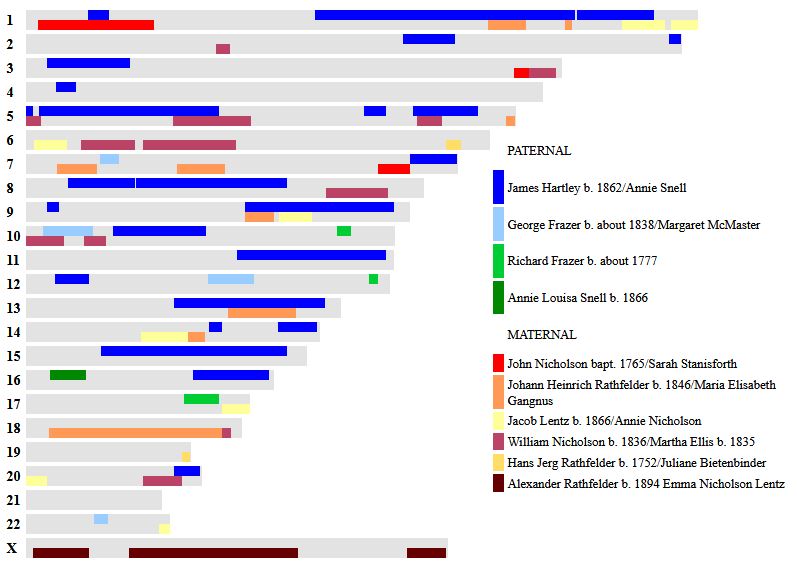
There are about 5M SNPs between the start of the Chromosome (16M) to where the AAABA Pattern starts at 21M. I have 4 of my siblings mapped out using visual phasing:

This shows on the paternal side (Frazer) that there is an AAAAA Pattern. That is represented above at the start of the Chromosome in blue. I am just missing Lori. Without looking at all her results, I see she has a full match with Heidi at the beginning of the Chromosome:

And here is the last Paternal Chromosome finished:

It was a lot of work, but now I have what should be the start and stop points for all the Paternal segments for me and my four siblings.
Summary
- I needed sequential IDs for my Access Queries to fill in missing alleles
- To do this I needed to go back to the beginning and re-import the raw data for six people
- I created a table for five siblings showing where they got their paternal and maternal alleles based on three principals.
- I went back to my Paternal Pattern Table and refined what I had already done
- I also added IDs to my Paternal Pattern Table
- Next up is to look at the Maternal Pattern Table and start filling in blanks using MS Access