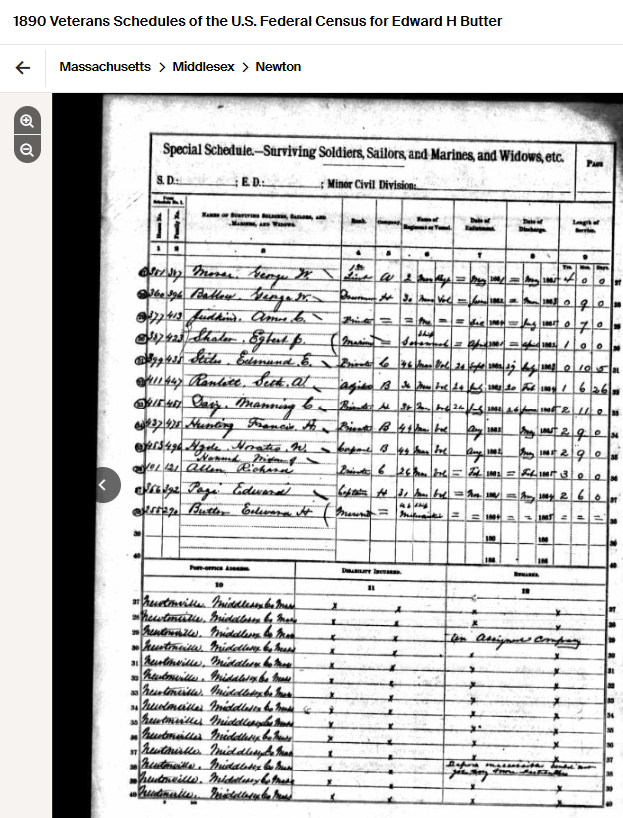
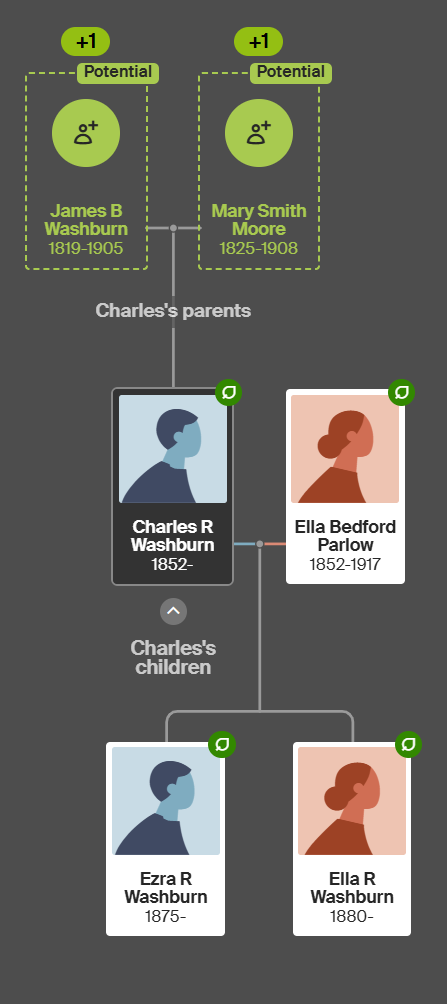
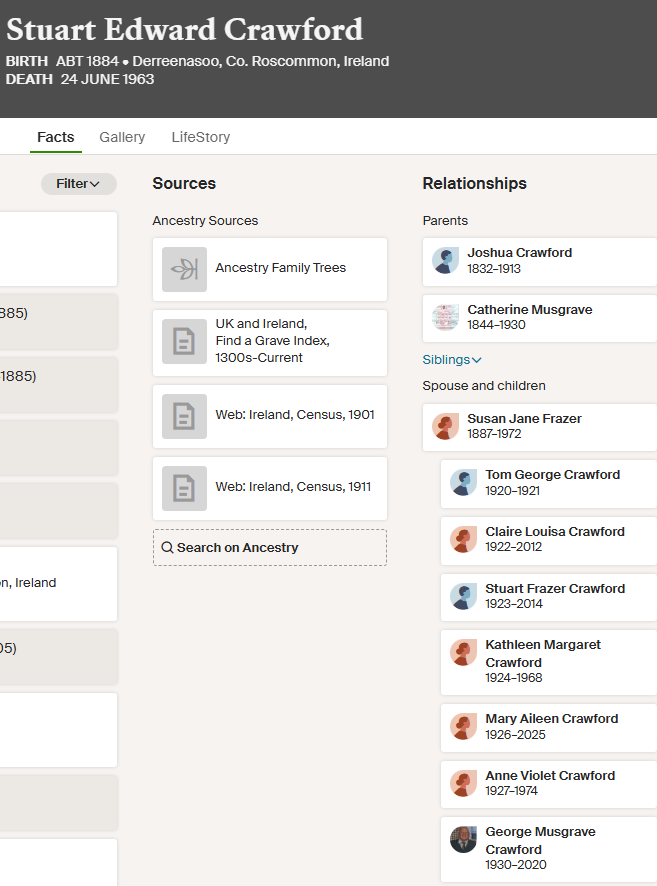
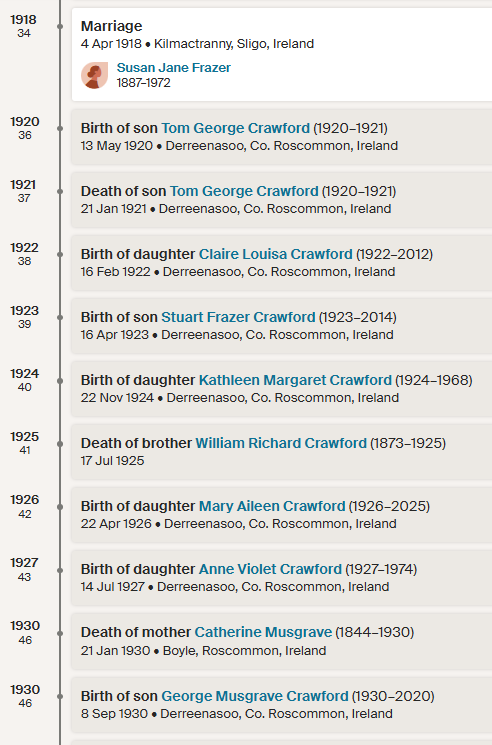
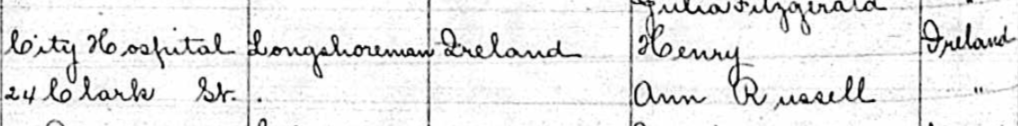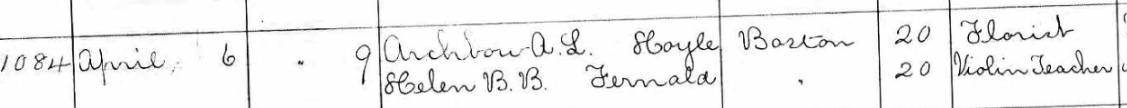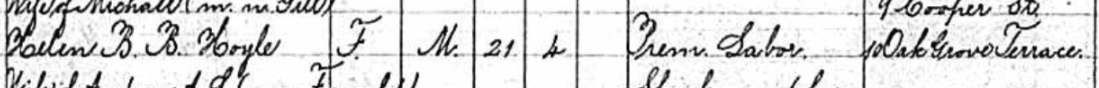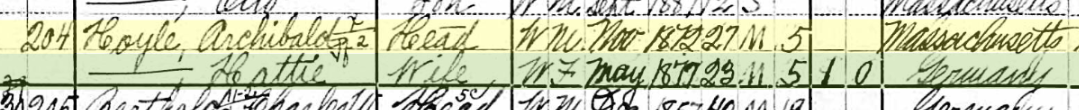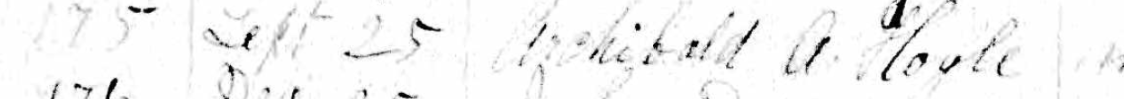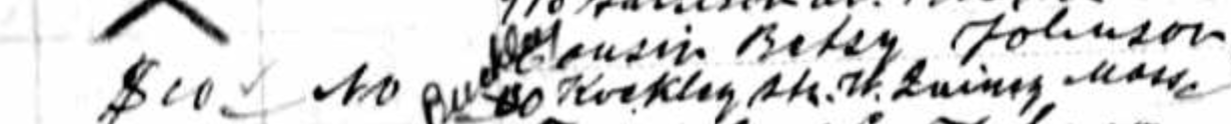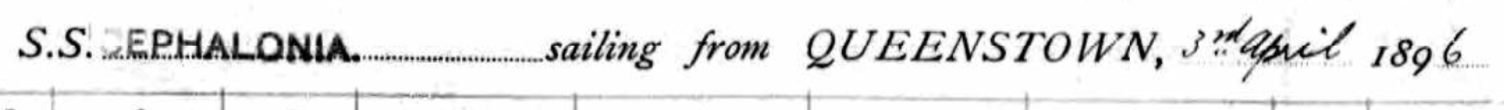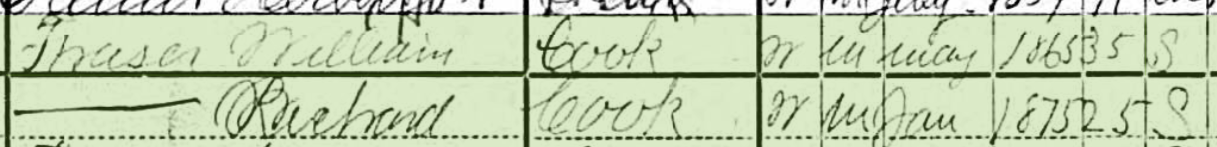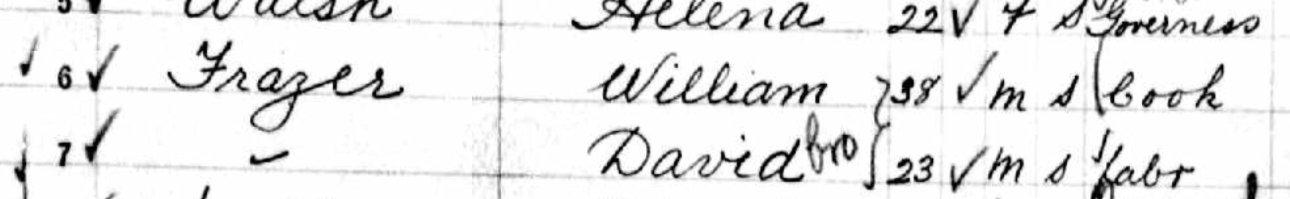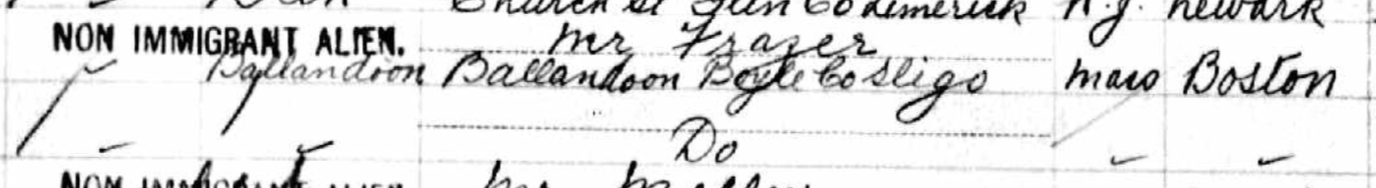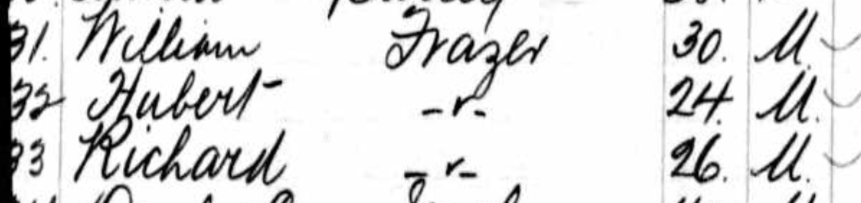I have been having a good working relationship with my wife’s niece Tina. She has been enthusiastically looking at the Butler genealogy that I have been looking at for many years. Before me, my wife’s Aunt Lorraine has been looking at the genealogy. Unfortunately, she had picked one of the wrong Edward Butlers’ death records which threw me off the track for many years. Tina picked up on the mistake which has helped a lot.
The 1880 Census
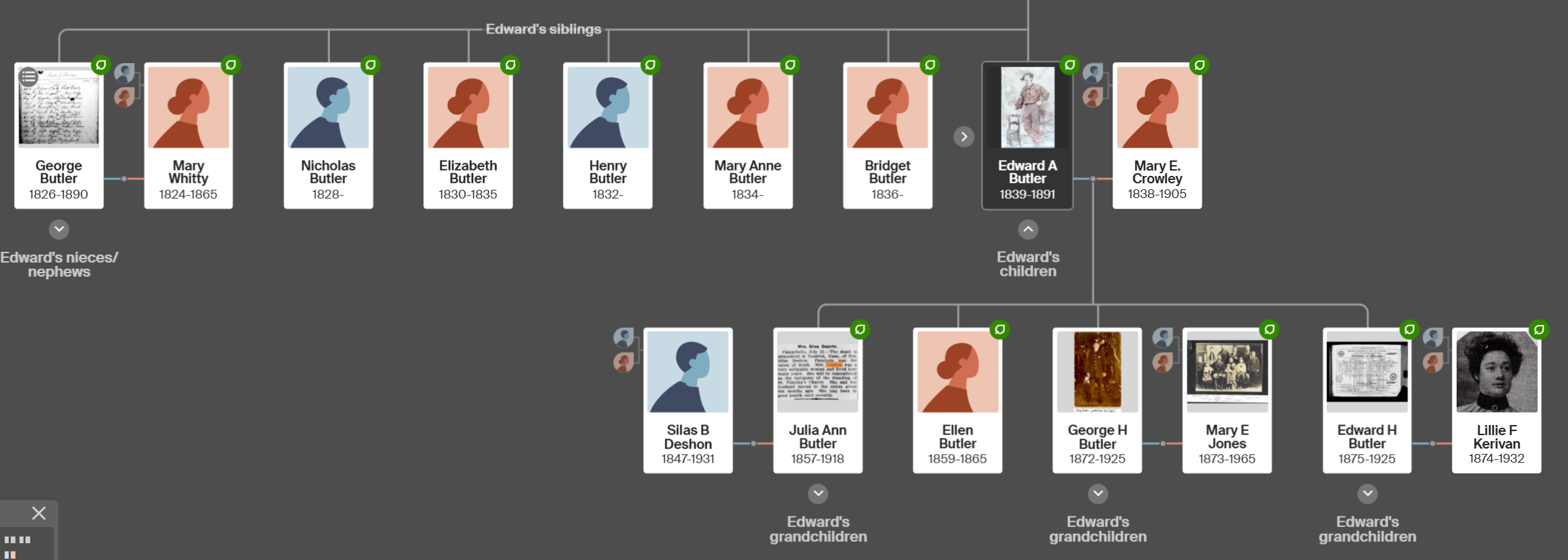
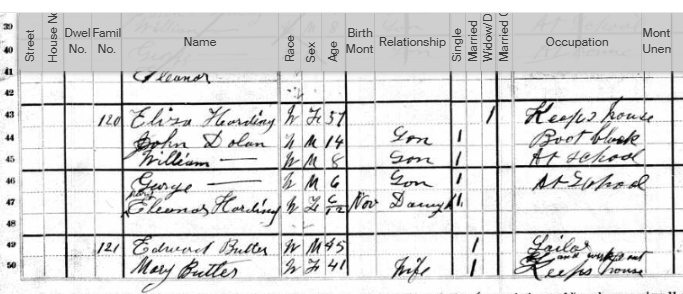
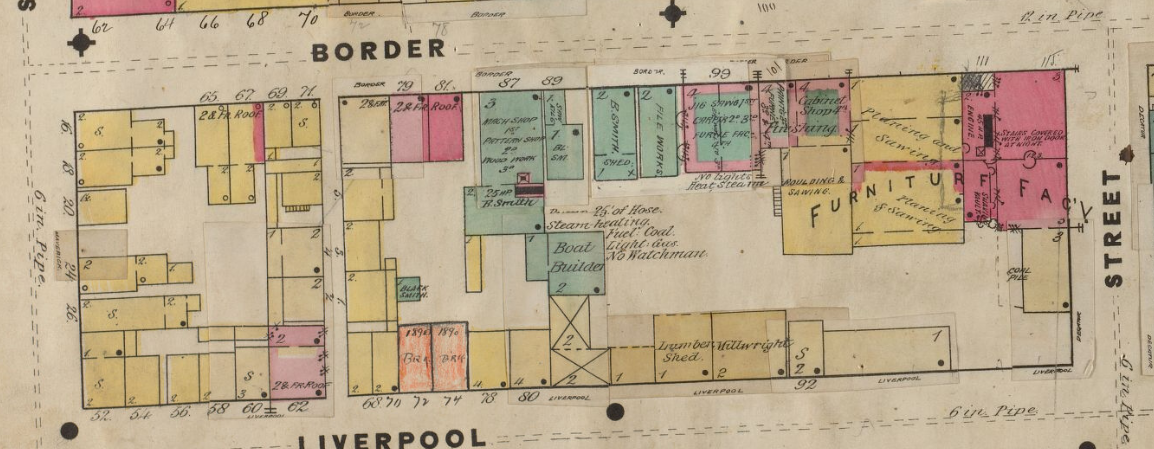
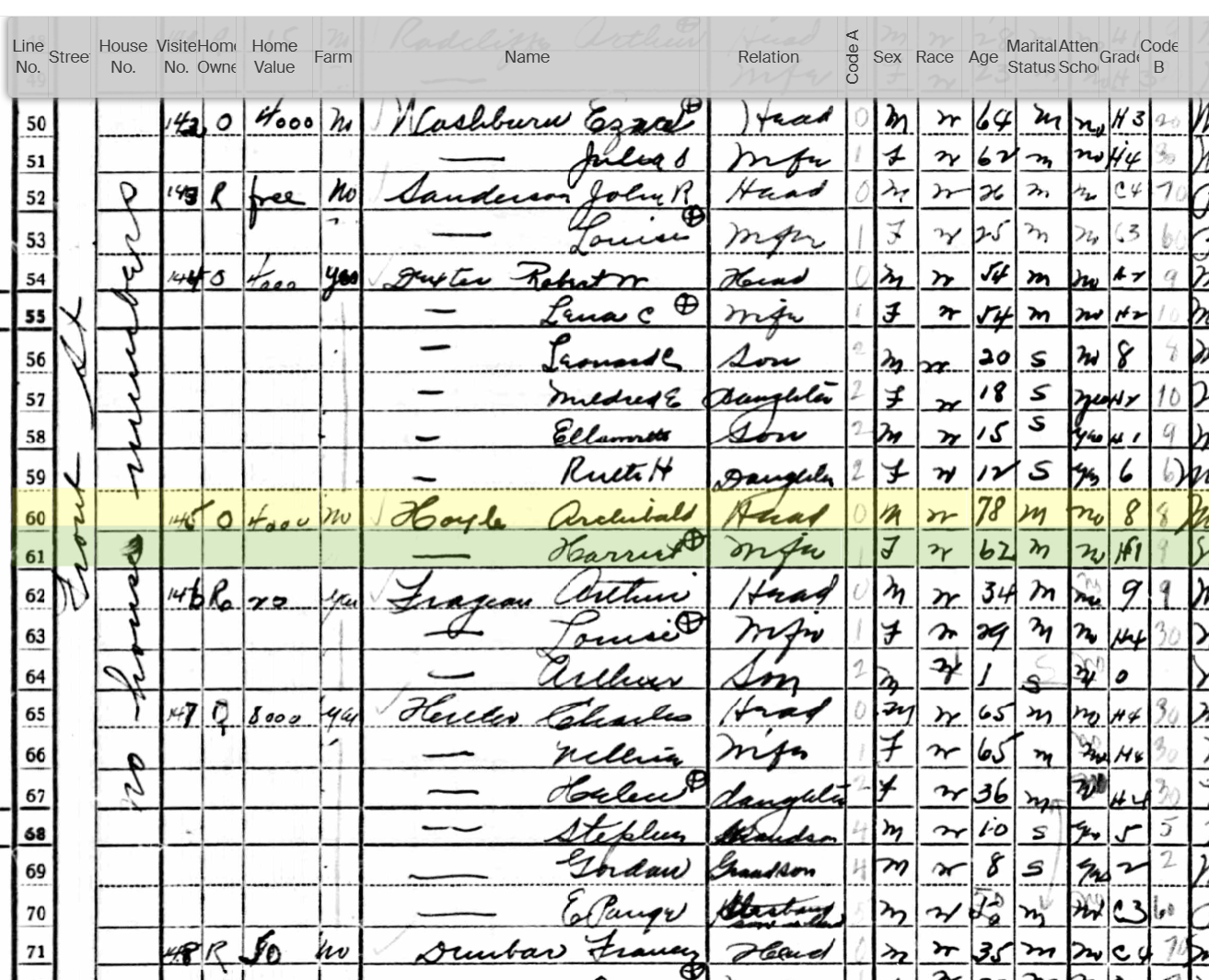
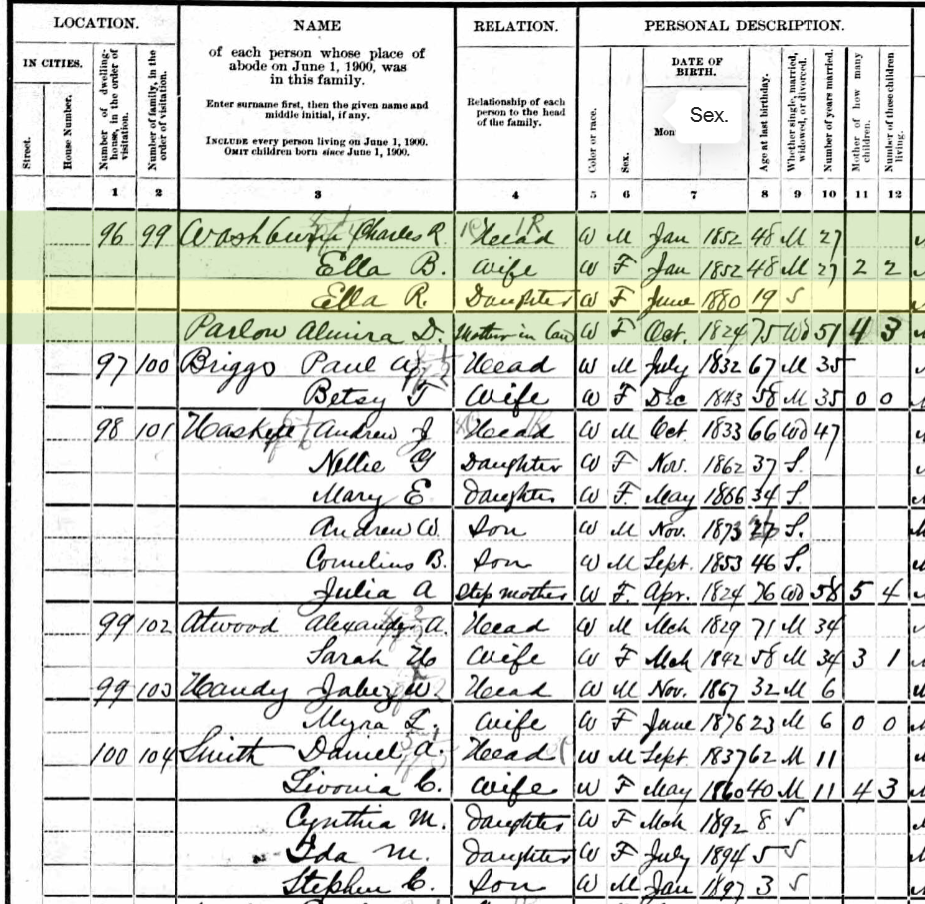
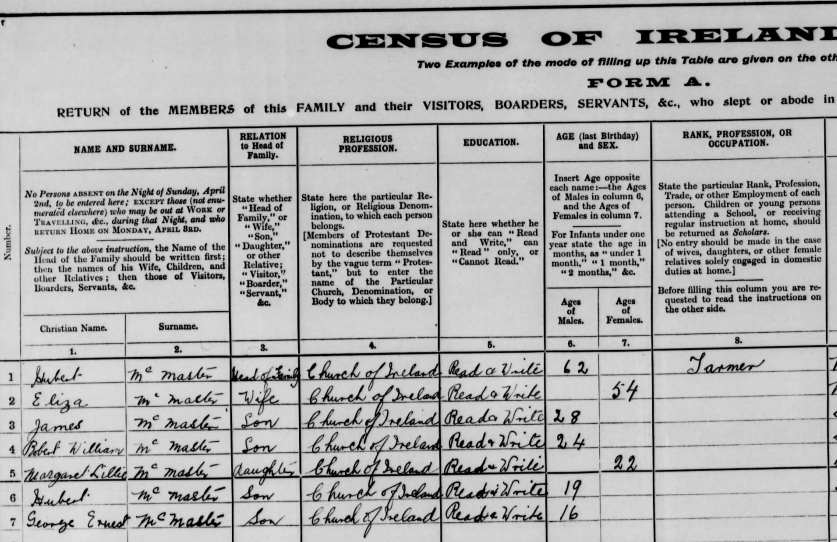
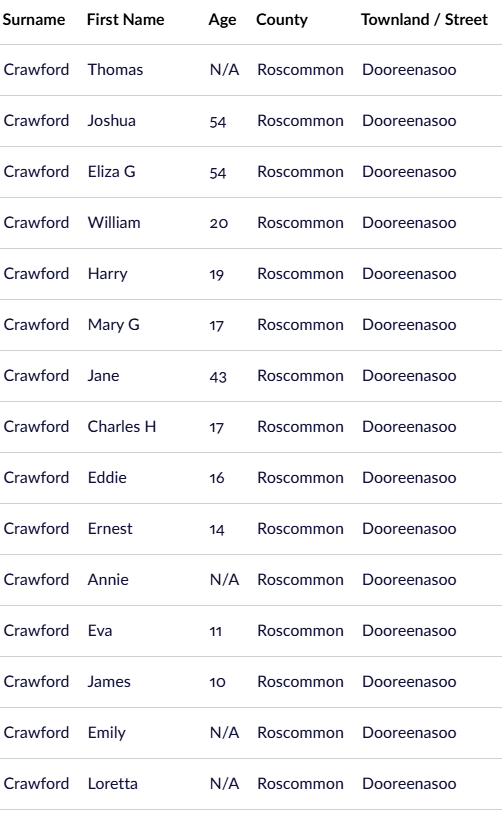
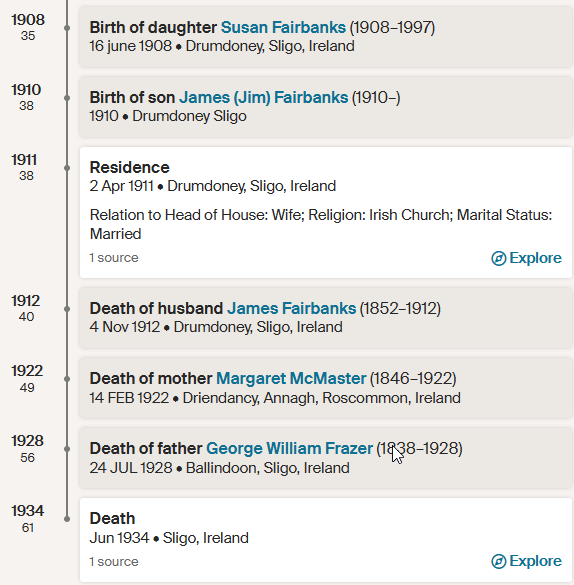
As I mentioned in my previous Blog, Tina also found the Butler familly in the 1880 Census. I had them in the 1860 and 1870 Census in Cincinnati. I had them in the Boston areas based on City Directories, but I could not find the family. Tina found them transcribed as Edward Butter and family. Here are the parents at the bottom of the page listed at Friend Street, Boston:

I am sure I have walked down Friend Street near North Station many times and not realized my wife’s 2nd great-grandfather and family lived there.
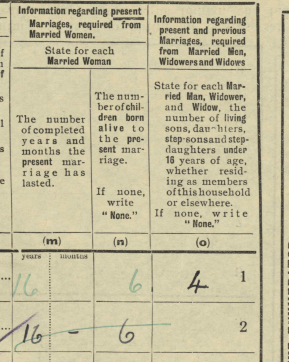
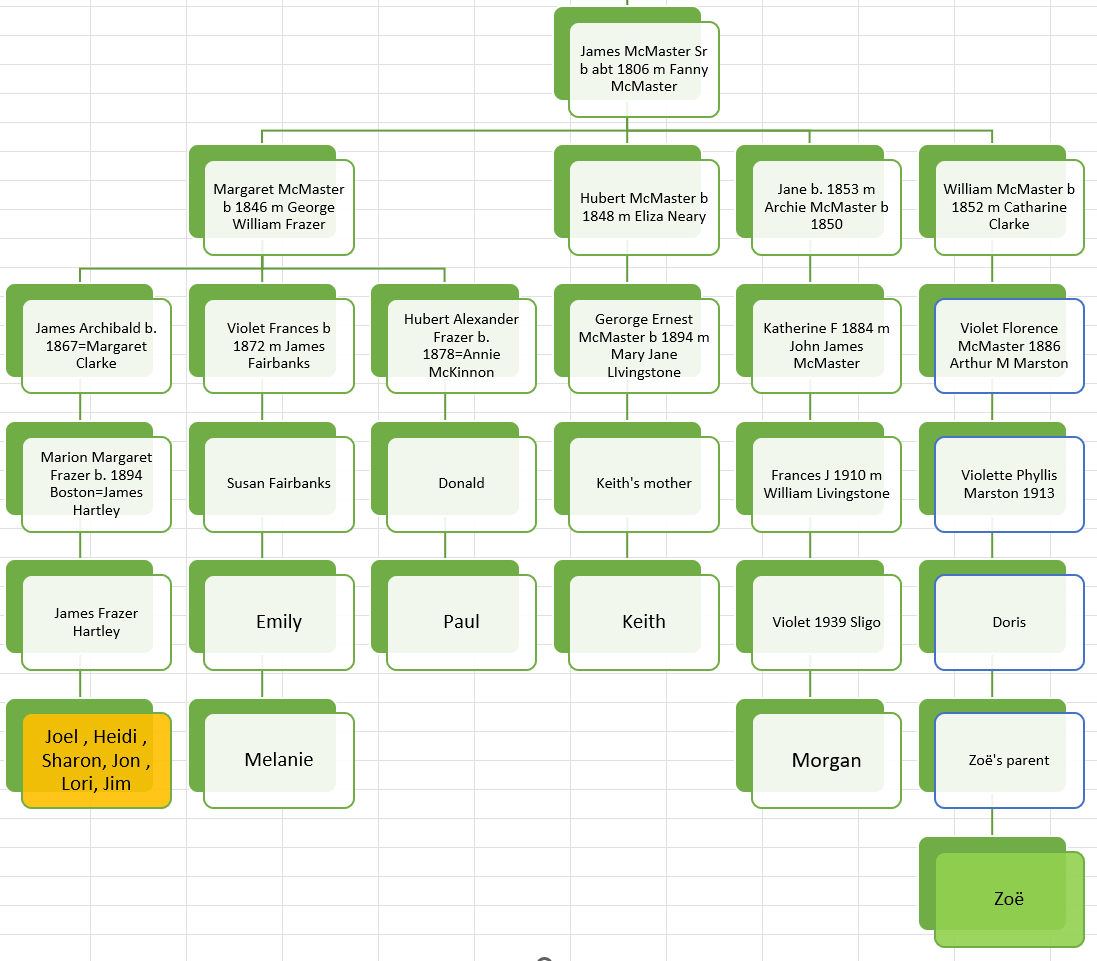
Tina has questions about the two sons in the 1880 Census:

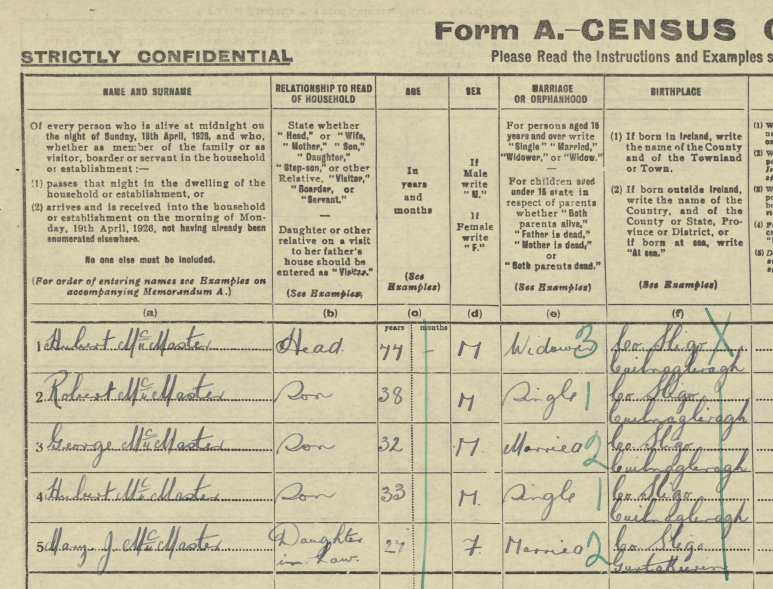
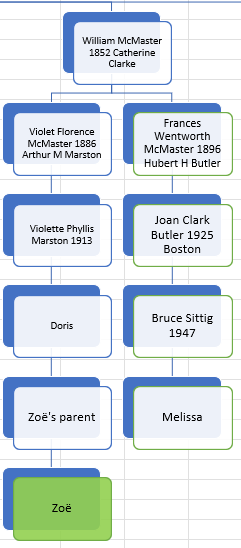
I believe that both sons were born in the Chicago, Illinois area as shown on the marriage and death records. However, we have not been able to find their birth records. Assuming they were both born in Illinois and the parents should show as the father born in Ireland and the mother born in N.B. (New Brunswick). However, that is not the case.
- The elder son George shows that he was born in Illinois and that his father and mother wAunere born in Ireland where the mother should be born in New Brunswick.
- Son #2, Edward shows as born in New Brunswick where he should show Illinois and his parents are shown correctly as being from Ireland and New Brunswick.
To me, that was a simple slip up by the enumerator. Tina, however, feels that this means that the two sons had a different mother. And that Edward was indeed born in New Brunswick. She seemed to think that her DNA results corroborated this view as she shows as a 1/2 third cousin to a George Butler Descendant.
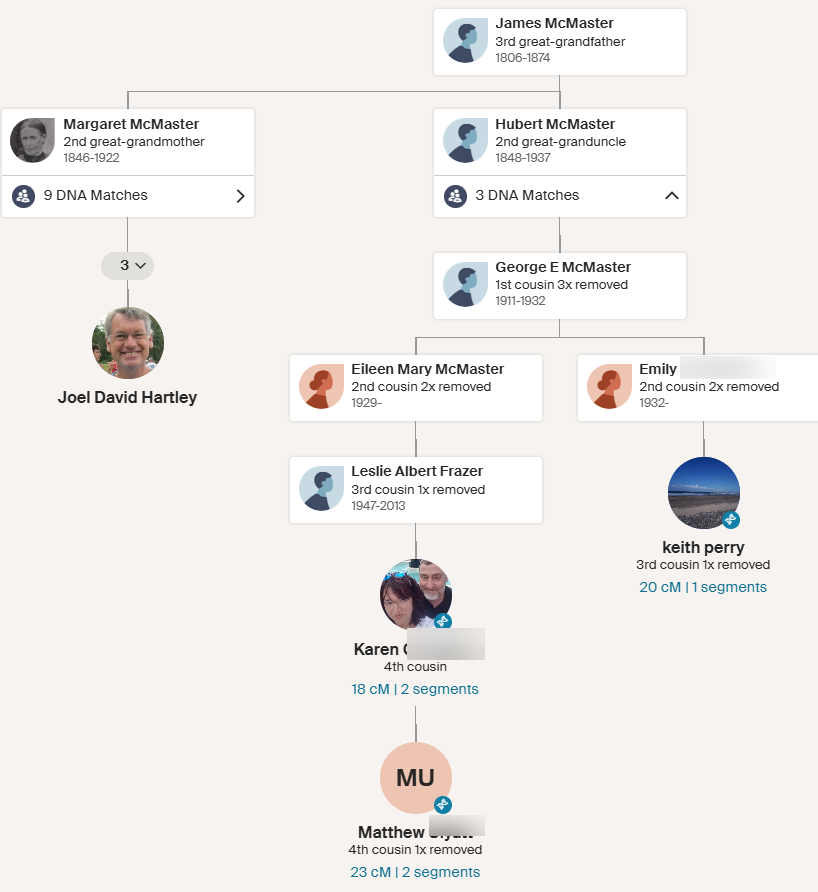
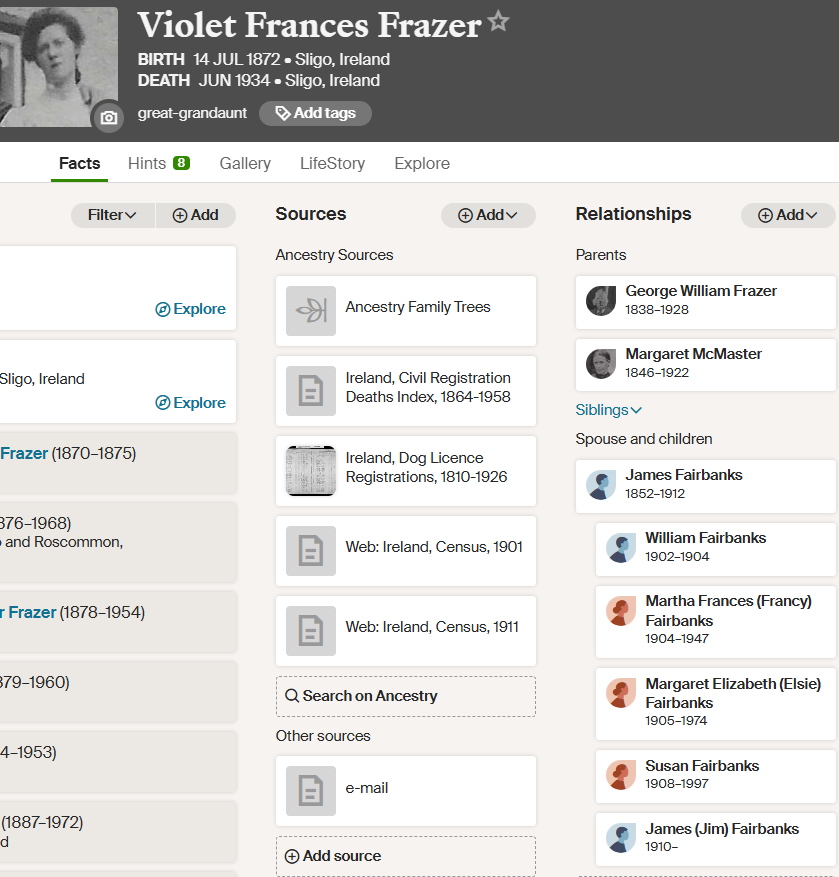
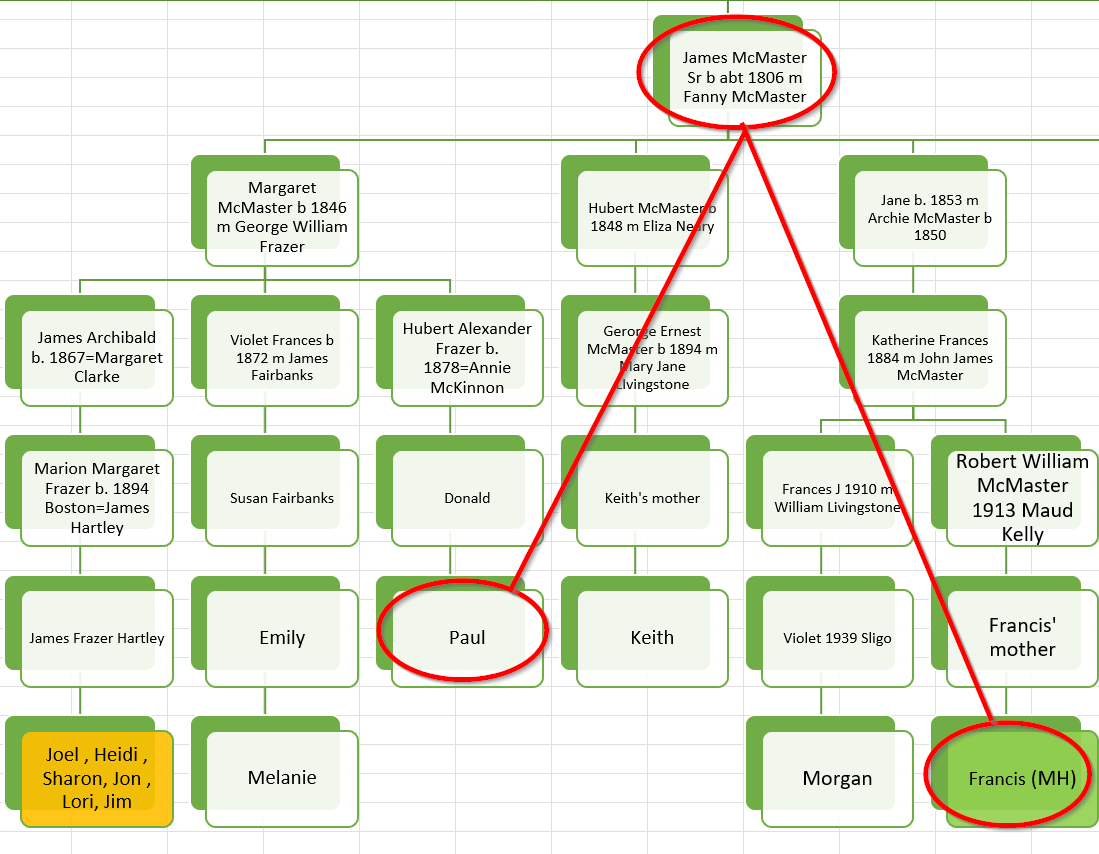
Edward and George Butler DNA
It should be easy to look at matches between the Edward Butler and George Butler descendants to see if this is the case. I have in the past taken DNA samples of my wife’s two Aunts: Lorraine and Suzy. Ancestry gives ranges of likely relationships given the DNA matches. I can put those matches into a spreadsheet and see what comes out. I also have access to my wife’s DNA results.
Aunt Lorraine
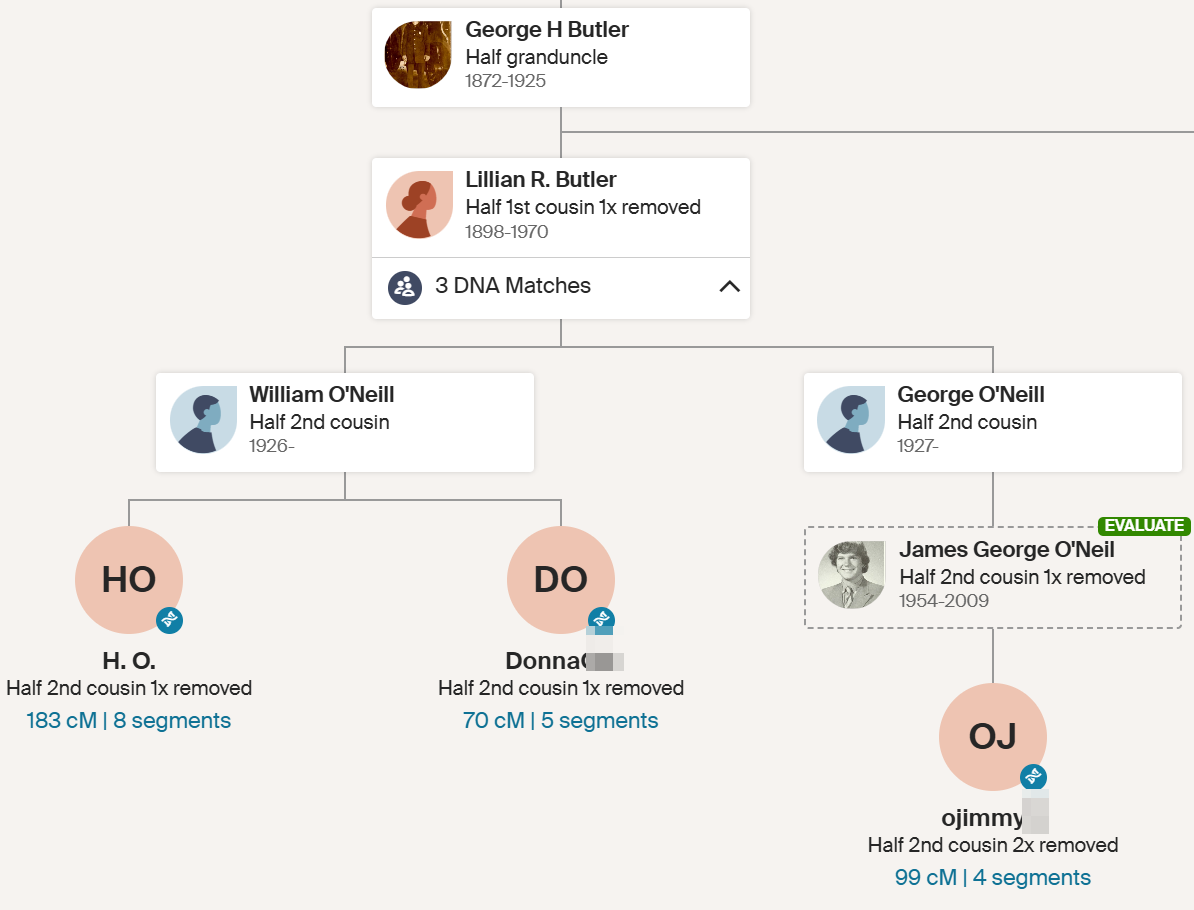
Aunt Lorraine has 7 matches to known descendants of George Butler:
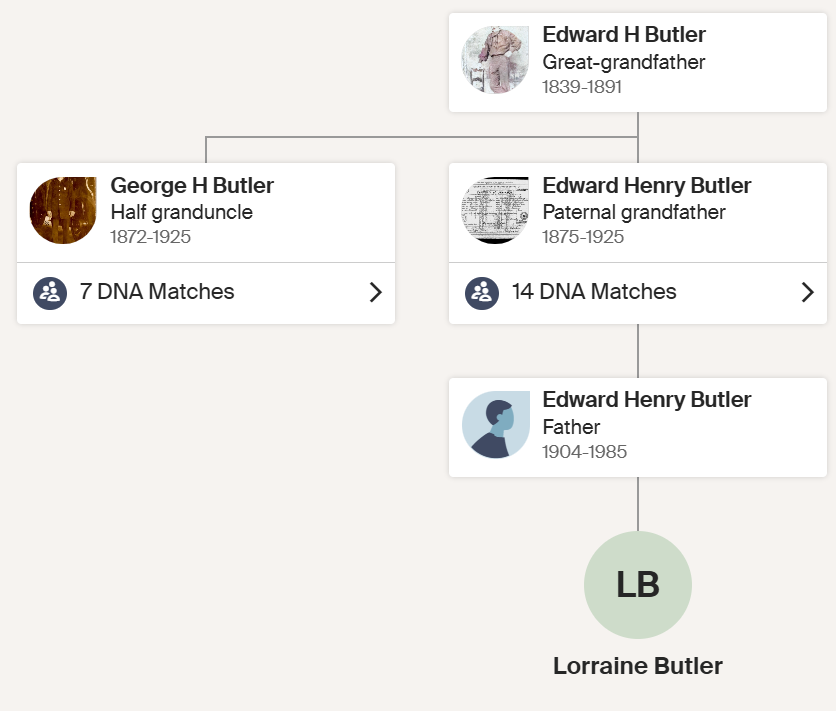
Here are the first three matches:
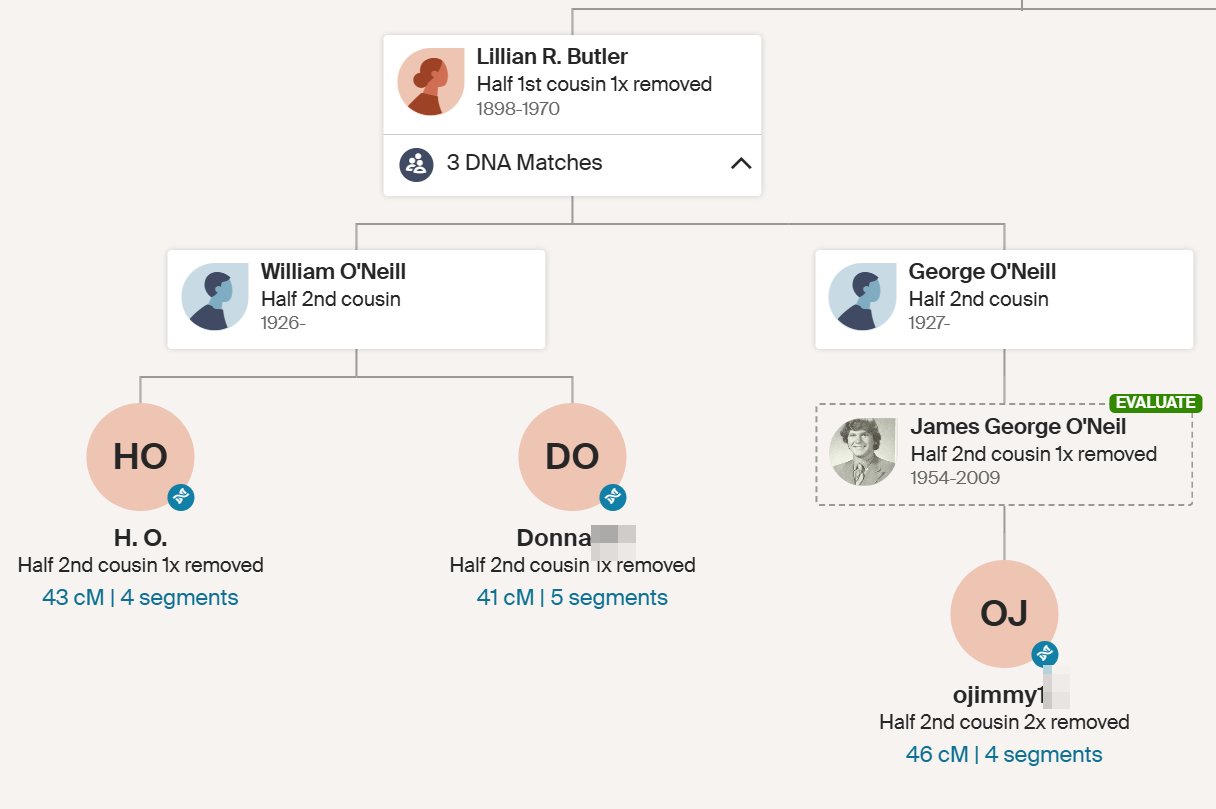
These all show as 1/2 relationships which seems to support Tina’s theory, but that often happens when Ancestry is unsure of relationships. I do not take these literally in most cases.
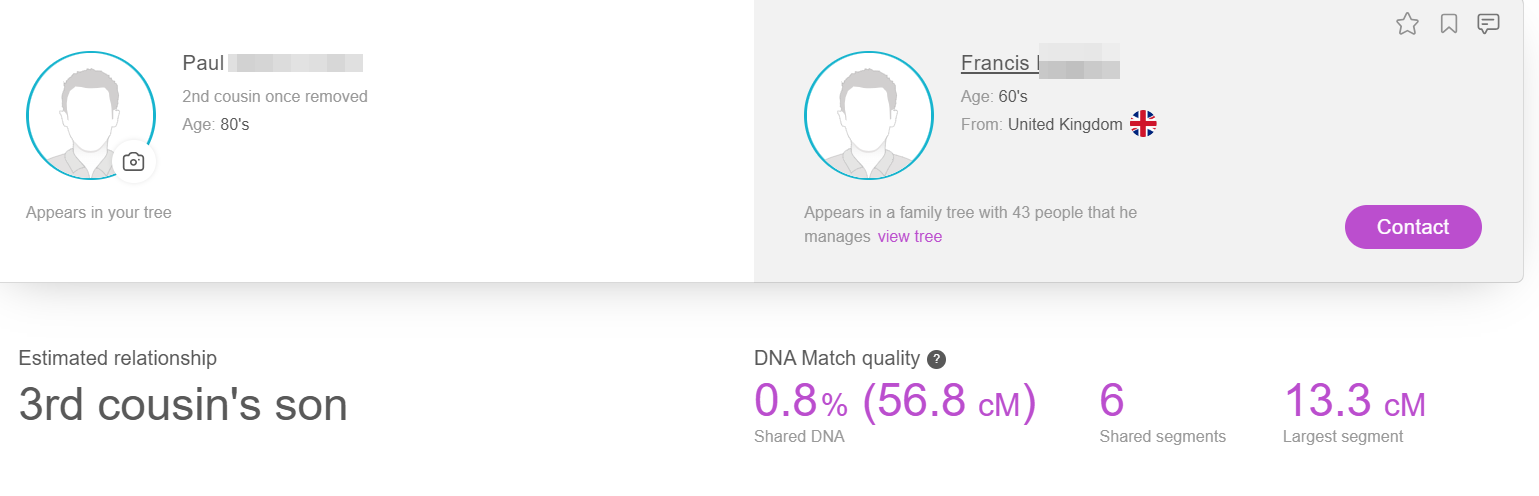
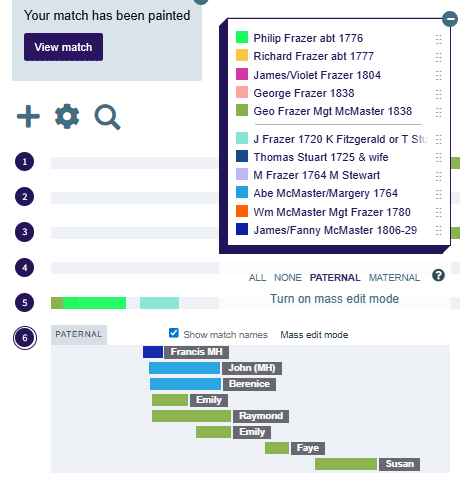
Here is the relationship to H.O:

Here is a predictor from the Shared cM Project 4.0:
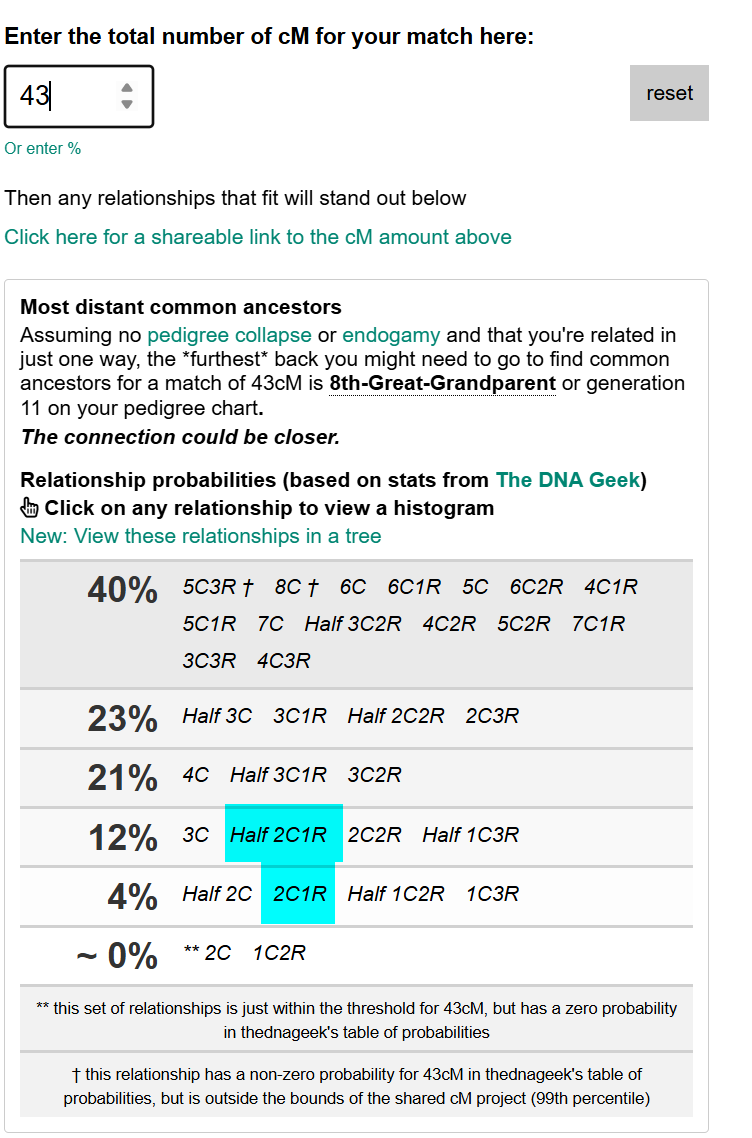
Here I have highlighted what I think the relationship should be and what Tina thinks it is. This first match supports the 1/2 2C1R. One for Tina!
Another interesting thing is that Ancestry has 25% of a 1/2 relationship and a 7% chance of a full relationship whereas the Shared cM Project Relationship predictor has 12% and 4% respectively. For my spreadsheet, I used the Shared cM Project Relationship Predictor as it was easier to use.
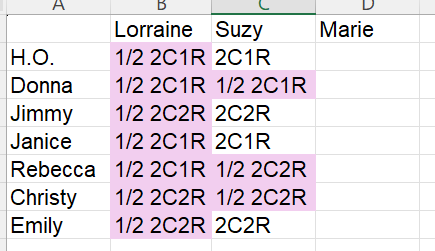
Here is my spreadsheet:

By the time I fill it all in, I should know if the DNA is saying that George and Edward were full brothers or half brothers.
Here is the Lorraine filled in for what she has a ThruLines:
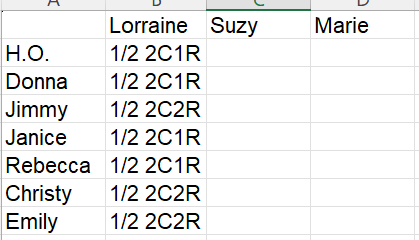
I plugged in the predicted relationship as above and where the 1/2 relationship was more likely than the full relationship, I chose that. This was the case for all of Lorraine’s ThruLine matches. There are other matches, but these are the matches with trees. This matches with what Tina says she is seeing with her DNA results. This makes me more convinced with what Tina is saying but not completely yet until I look at Suzy and Marie. Lorraine may have inherited less of the George side DNA for some reason.
Aunt Suzy AKA Virginia
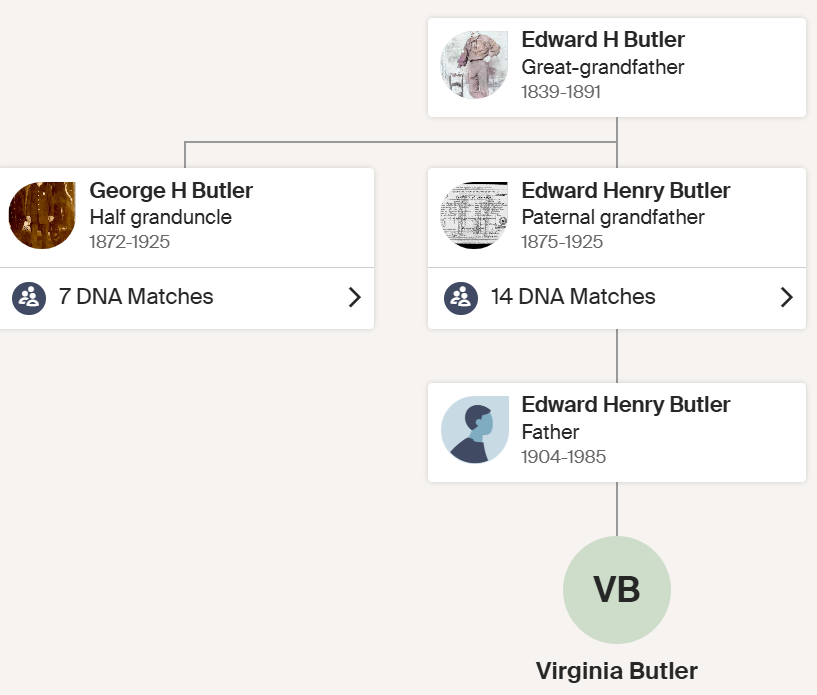
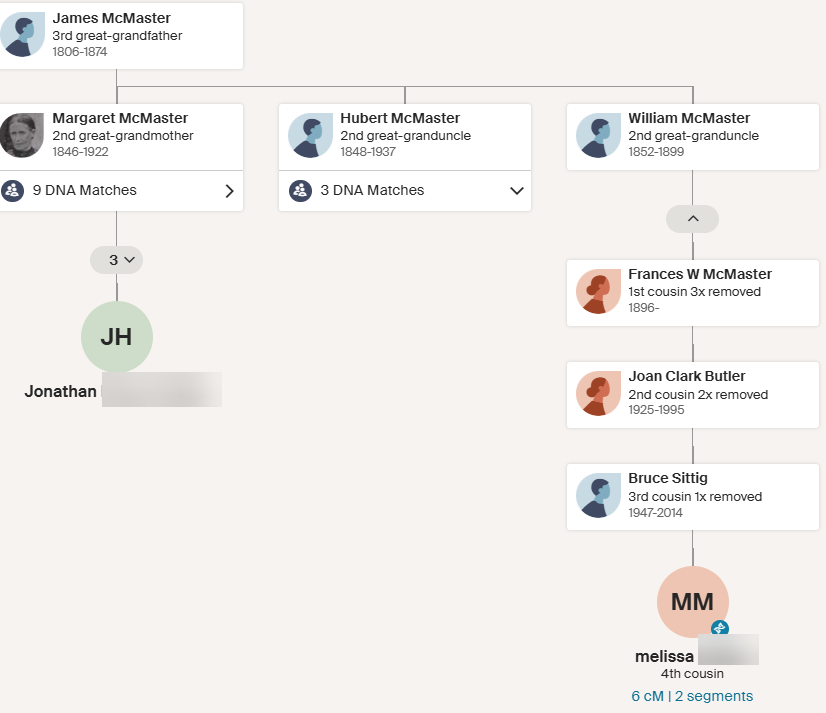
Aunt Suzy also has 7 matches to the George H Butler side:
However, her matches are much larger. Now the tables have turned:

For H.O. and Suzy, there is a 50% chance they have a 2C1R relationship and 7% chance of a half 2C1R relationship.
The results are not totally convincing for Aunt Suzy:
More matches suggest the full relationship, but Lorraine’s result strongly favor the 1/2 relationship. One thing the chart does not represent is how strongly the match favors a half or full relationship. However, that would be more difficult to show and evaluate. For example in Lorrine’s example with H.O., the half relationship was only 12% likely and and the full relationship was 4% likely. I do not know how that compares with Suzy and H.O. where the full relationship was 50% likely and the 1/2 relationship was 7% likely.
Marie
Marie would have to have a lot of full relationships indicated to overturn Lorraine’s results.
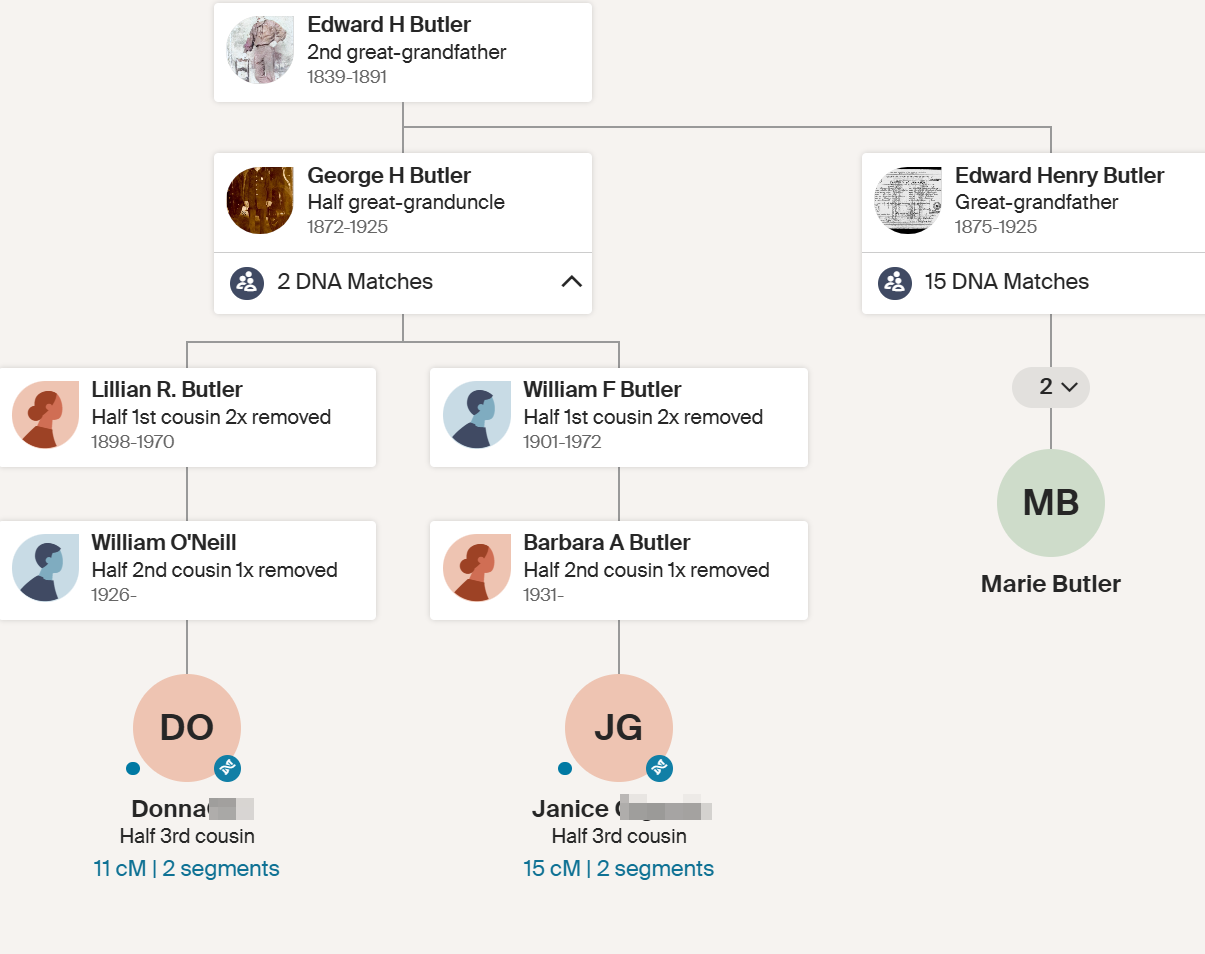
Marie only has 2 George Butler side matches and those matches are quite low.
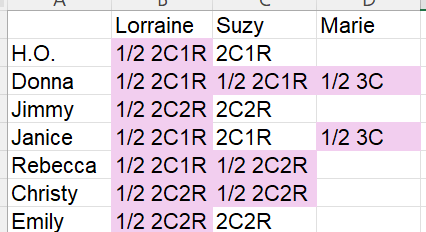
So for 16 matches, 12 favor the 1/2 relationship. To me, that says that there is a 75% chance that George and Edward are half brothers. Still, there is a 25% that they could be full brothers. I think that I would be more convinced if I saw all pink on the chart above.
Still, Tina has a theory and the DNA certainly give more credence to her theory.
Summary and Conclusions
- I checked the DNA matches between descendants of the George Butler who was born 1872 and my wife and her two Aunts
- I used the relationship predictor at the Shared cM Project. At the level of relationship, say 2nd cousin 1 removed the predictor would favor a full relationship or 1/2 relationship.
- I put the results of a full or 1/2 relationship in a spreadsheet. 3 out of 4 DNA matches favored the half relationship. That suggests that it is three times as likely that the George H Butler born 1872 and Edward Henry Butler are half brothers. However, that does not rule out the 25% chance that they were full brothers.